Off the Top: Digital Identity Entries
Showing posts: 1-15 of 15 total posts
Selective Sociality and Social Villages
The web provides wonderful serendipity on many fronts, but in this case it brought together two ideas I have been thinking about, working around, and writing about quite a bit lately. The ideas intersect at the junction of the pattern of building social bonds with people and comfort of know interactions that selective sociality brings.
The piece that struck me regarding building and identifying a common bond with another person came out of Robert Paterson's "Mystery of Attraction" post (it is a real gem). Robert describes his introduction and phases of getting to know and appreciate Luis Suarez (who I am a huge fan of and deeply appreciate the conversations I have with him). What Robert lays out in his introduction (through a common friend on-line) is a following of each other's posts and digital trail that is shared out with others. This builds an understanding of each others reputation in their own minds and the shared interest. Upon this listening to the other and joint following they built a relationship of friendship and mutual appreciation (it is not always mutual) and they began to converse and realized they had a lot more in common.
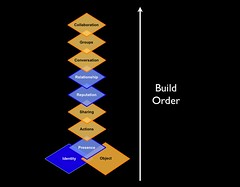 What Robert echos is the Elements in Social Software and its build order. This build order is common in human relationships, but quite often social software leaves out steps or expects conversations, groups, and collaboration to happen with out accounting for the human elements needed to get to this stage. Quite often the interest, ideas, and object (all social objects) are the stimulus for social interaction as they are the hooks that connect us. This is what makes the web so valuable as it brings together those who are near in thought and provides a means to connect, share, and listen to each other. I really like Robert's analogy of the web being like university.
What Robert echos is the Elements in Social Software and its build order. This build order is common in human relationships, but quite often social software leaves out steps or expects conversations, groups, and collaboration to happen with out accounting for the human elements needed to get to this stage. Quite often the interest, ideas, and object (all social objects) are the stimulus for social interaction as they are the hooks that connect us. This is what makes the web so valuable as it brings together those who are near in thought and provides a means to connect, share, and listen to each other. I really like Robert's analogy of the web being like university.
Selective Sociality of Villages
The piece that resonated along similar threads to Robert's post is Susan Mernit's "Twitter & Friend Feed: The Pleasure of Permissions". Susan's post brings to light the value of knowing who you are sharing information with and likes the private or permission-based options that both Twitter and FriendFeed offer. This selective sociality as known Local InfoCloud of people and resources that are trusted and known, which we use as resources. In this case it is not only those with whom we listen to and query, but those with whom we share. This knowing who somebody is (to some degree) adds comfort, which is very much like Robert Patterson and Luis Suarez#039; villages where people know each other and there is a lot of transparency. Having pockets where our social armor is down and we can be free to share and participate in our lives with others we know and are familiar to us is valuable.
I am found these two pieces quite comforting as they reflect much of what I see in the physical community around me as well as the work environments I interact with of clients and collaborators. The one social web service I have kept rather private is Twitter and I really want to know who someone is before I will accept them as a connection. This has given me much freedom to share silly (down right stupid - in a humorous way) observations and statements. This is something I hear from other adults around kids playgrounds and practices of having more select social interactions on line in the services and really wanting to connect with people whom they share interests and most often have known (or followed/listened to) for sometime before formally connecting. Most often these people want to connect with the same people on various services they are trying out, based on recommendation (and often are leaving a service as their friends are no longer there or the service does not meet their needs) of people whom they trust. This is the core of the masses who have access and are not early adopters, but have some comfort with the web and computers and likely make up 80 to 90 percent of web users.
[Comments are open (with moderation as always) on this post at Selective Sociality and Social Villages :: Personal InfoCloud]
6th Internet Identity Workshop Coming Up
The other event that I am finding to be fantastic is also in the Bay Area the week of May 12th is the 6th Internet Identity Workshop. This is the event for people working around identity related issues (any social application or service) that are now the core of nearly all products on the web and intranet. I have found that those who attend this event really grasp the meaning and deep impact of identity along with the needed tools and services around identity. It is really rare that I find somebody talking or writing about identity related issues in a smart manner that has not been part of one of the past IIW events.
As the discussion around the social graph has become hot identity (and the issue of privacy) has come to the forefront even more. Most services are not dealing with identity in an intelligent manner that is recognizable by a huge majority of people who are using these digital services. Much of the mangled discussion around social graph is missing solid understanding from a digital identity perspective and the use and reuse of statements of relationship that do not transcend various services.
Discussions around persona (not the IA persona variety) and identity abound and the need for services that grasp these differences are worked through. The need for better understanding the incredible value the role of identity in tagging services has also been discussed here, which is something many services do not grasp and are doing a dis-service to the people who want to tag items in their own perspective and context to ease their own refinding of the object (Twine really needs a much better understanding of tagging as their automated tagging is incredibly poor and missing many tangents for understanding that need to be applied for full and proper understanding of the objects in their service).
I am really hoping to get to part of the IIW event this time around my workshop in Las Vegas to continue with the great identity conversations from the past IIW events.
DataPortability Video is Place to Start Understanding
Marchall Kirkpatrick at ReadWriteWeb has posted a good background about New Video Explains the Basics of Data Portability. The DataPortability - Connect, Control, Share, Remix video is under 2 minutes in length and explains the reasons why the DataPoratbility.org group is important. It aims to ease the pain many are experiencing as they use more social media, social web services, social networks, and/or social computing services in their personal and work life.
Control
The biggest piece in this for me is control with translates to services respecting privacy wishes among other desires around trust and control of sharing. As Tom Raftery points out With the rising interest in, and use of Social Networks (FaceBook, Plaxo et al) there is growing unease in what those sites are doing with your data, never mind the inconvenience of uploading all your data every time you join a new site. The DataPortability.org aims to include in its focus data that is "shared between our chosen (and trusted) tools and vendors".
I have been working around the edges on a project whose aim is to respect these privacy wishes. This is one of the things that really needs to be at the core of all services entering into this market segment.
A Stale State of Tagging?
David Weinberger posted a comment about Tagging like it was 2002, which quotes Matt Mower discussing the state of tagging. I mostly agree, but not completely. In the consumer space thing have been stagnant for a while, but in the enterprise space there is some good forward movement and some innovation taking place. But, let me break down a bit of what has gone on in the consumer space.
History of Tagging
The history of tagging in the consumer space is a much deeper and older topic than most have thought. One of the first consumer products to include tagging or annotations was the Lotus Magellan product, which appeared in 1988 and allowed annotations of documents and objects on one's hard drive to ease finding and refinding the them (it was a full text search which was remarkably fast for its day). By the mid-90s Compuserve had tagging for objects uploaded into its forum libraries. In 2001 Bitzi allowed tagging of any media what had a URL.
The down side of this tagging was the it did not capture identity and assuming every person uses words (tag terms) in the same manner is a quick trip to the tag dump where tags are not fully useful. In 2003 Joshua Schacter showed the way with del.icio.us that not only allowed identity, upon which we can disambiguate, but it also had a set object in common with all those identities tagging it. The common object being annotated allows for a beginning point to discern similarity of identityĵs tag terms. Part of this has been driven on Joshua's focus on the person consuming the content and allowing a means for that consumer to get back to their information and objects of interest. (It is around this concept that folksonomy was coined to separate it from the content publisher tagging and non-identity related tagging.) This picked up on the tagging for one's self that was in Lotus Magellan and brings it forward to the web.
Valuable Tagging
It was in del.icio.us that we saw tagging that really did not work well in the past begin to become valuable as the clarity in tag terms that was missing in most all other tagging systems was corrected for in the use of a common object being tagged and the identity of the tagger. This set the foundation for some great things to happen, but have great things happened?
Tagging Future Promise
Del.icio.us set many of out minds a flutter with insight into the dreams of the capability of tagging having a good foothold with proper structure under them. A brilliant next step was made by RawSugar (now gone) to use this structure to make ease of disambiguating the tag terms (by appleseed did you mean: Johnny Appleseed, appleseeds for gardening/farming, the appleseed in the fruit apple, or appleseed the anime movie?). RawSugar was a wee bit before its time as it is a tool that is needed after there tagging (particularly folksonomy related tagging systems) start scaling. It is a tool that many in enterprise are beginning to seek to help find clarity and greater value in their internal tagging systems they built 12 to 18 months ago or longer. Unfortunately, the venture capitalists did not have the vision that the creators of RawSugar did nor the patience needed for the market to catch-up to the need in a more mature market and they pulled the plug on the development of RawSugar to put the technology to use for another purpose (ironically as the market they needed was just easing into maturity).
The del.icio.us movement drove blog tags, laid out by Technorati. This mirrored the previous methods of publisher tagging, which is most often better served from set categories that usually are derived from a taxonomy or simple set (small or large) of controlled vocabulary terms. Part of the problem inherent in publisher tags and categories is that they are difficult to use outside of their own domain (however wide their domain is intended - a specific site or cross-sites of a publisher). Using tags from one blog to another blog has problems for the same reason that Bitzi and all other publisher tags have and had problems, they are missing identity of the tagger AND a clear common object being tagged. Publisher tags can work well as categories for aggregating similar content within a site or set of commonly published sites where a tag definition has been set (but that really makes them set categories) and used consistently. Using Technorati tag search most often surfaces this problem quickly with many variation of tag use surfacing or tag terms being used to attract traffic for non-related content (Technorati's keyword search is less problematic as it relies on the terms being used in context in the content - unfortunately the two searches have been tied together making search really messy at the moment). There is need for an improved tool that could take the blog tags and marry them to the linked items in the content (if that is what is being talked about - discerning predicate in blog tags is not clear yet).
Current Tools that Advanced
As of a year ago there were more than 140 social bookmarking tools in the consumer space, but there was little advancement. But, there are a few services that have innovated and brought new and valuable features to market in tagging. As mentioned recently Ma.gnolia has done a really good job of taking the next steps with social interaction in social bookmarking. Clipmarks pioneered the sub-page tagging and annotation in the consumer tagging space and has a really valuable resource in that tool. ConnectBeam is doing some really good things in the enterprise space, mostly taking the next couple steps that Yahoo MyWeb2 should have taken and pairing it with enterprise search. Sadly, del.icio.us (according to comments in their discussion board) is under a slow rebuilding of the underlying framework (but many complaints from enterprise companies I have worked with and spoken indepth with complain del.icio.us continually blocks their access and they prefer not to use the service and are finding current solutions and options to be better for them).
A Long Way to Go
While there are examples that tagging services have moved forward, there is so much more room to advance and improve. As people's own collection of tagged pages and objects have grown the tools are needed to better refind them. This will require time search and time related viewing/scanning of items. The ability to use co-occurance of tag terms (what other tags were used on the object), with useful interfaces to view and scan the possibilities.
Portability and interoperability is extremely important for both the individual person and enterprise to aggregate, migrate, and search across their collections across services and devices (now that devices have tagging and have had for some time, as in Mac OS X Tiger and now Vista). Enterprises should also have the ability to move external tagged items in through their firewall and publish out as needed, mostly on an employee level. There is also desire to have B2B tagging with customers tagging items purchased so the invoicing can be in the customers terminology rather than the seller terminology.
One of the advances in personal tagging portability and interoperability can easily be seen when we tag on one device and move the object to a second device or service (parts of this are not quite available yet). Some people will take a photo on their mobile phone and add quick tags like "sset" and others to a photo of a sunset. They send that photo to a service or move it to their desktop (or laptop) and import the photo and the tag goes along with it. The application sees the "sset" and knows the photo was transfered from that person's mobile device and knows it is their short code for "sunset" and expands the tag to sunset accordingly. The person then adds some color attribute tags to the photo and moves the photo to their photo sharing service of choice with the tags appended.
The current tools and services need tools and functionality to heal some of the messiness. This includes stemming to align versions of the same word (e.g. tag, tags, tagging, bookmark, bookmarking). Tag with disambiguation in mind by offering co-occurrence options (e.g. appleseed and anime or johnny or gardening or apple). String matching to identify facets for time and date, names (from your address book), products, secret tag terms (to have them blocked from sharing), etc. (similar to Stikkit and GMail).
Monitoring Tools
Enterprise is what the next development steps really need to take off (these needs also apply to the power knowledge worker as well). The monitoring tools for tags from others and around objects (URLs) really need to fleshed out and come to market. The tag monitoring tools need to become granular based on identity and co-occurance so to more tightly filter content. The ability to monitor a URL and how it is tagged across various services is a really strong need (there are kludgy and manual means of doing this today) particularly for simple and efficient tools (respecting the tagging service processing and privacy).
Analysis Tools
Enterprise and power knowledge workers also are in need of some solid analysis tools. These tools should be able to identify others in a service that have similar interests and vocabulary, this helps to surface people that should be collaborating. It should also look at shifts in terminology and vocabulary so to identify terms to be added to a taxonomy, but also provide an easy step for adding current emergent terms to related older tagged items. Identify system use patterns.
Just the Tip
We are still at the tip of the usefulness of tagging and the tools really need to make some big leaps. The demands are there in the enterprise marketplace, some in the enterprise are aware of them and many more a getting to there everyday as the find the value real and ability to improve the worklife and workflow for their knowledge workers is great.
The people using the tools, including enterprise need to grasp what is possible beyond that is offered and start asking for it. We are back to where we were in 2003 when del.icio.us arrived on the scene, we need new and improved tools that understand what we need and provide usable tools for those solutions. We are developing tag islands and silos that desperately need interoperability and portability to get real value out of these stranded tag silos around or digital life.
Why Ma.gnolia is One of My Favorite Social Bookmarking Tools
After starting the Portable Social Network Group in Ma.gnolia yesterday I received a few e-mails and IMs regarding my choice. Most of the questions were why not just use tags and del.icio.us. After I posted my Ma.Del Tagging Bookmarklet post I have had a lot of questions about Ma.gnolia and my preference as well as people thought I was not a fan of it. I have been thinking I would blog about my usage, but given my work advising on social bookmarking and social web, I shy away talking about what I use as what I like is likely not what is going to be a good fit for others. But, my work is one of the reasons I want to talk about what I like using as nearly every customer of mine and many presentation attendees look at del.icio.us first (it kicked the door wide open with a tool that was light years ahead of all others), but it is not for everybody and there are many other options. Much of my work is with enterprise and organizations of various size, which del.icio.us is not right for them for privacy reasons. I still add to del.icio.us along with my favorite as there are many people that have subscribed to the at feed as they derive value from that subscription so I take the extra step to keep that feed as current.
Ma.gnolia Offers Great Features for Sociality
I have two favorite tools for my own personal social bookmarking reasons Ma.gnolia and Clipmarks (I don't think I have anything publicly shared in Clipmarks). First the later, I use Clipmarks primarily when I only want to bookmark a sub-page element out on the web, which are paragraphs, sentences, quotes, images, etc.
I moved to try Ma.gnolia again last Fall when something changed in del.icio.us search and the results were not returning things that were in del.icio.us. My trying Ma.gnolia, by importing all of my 2200 plus bookmarks not only allowed me to search and find things I wanted, but I quickly became a fan of their many social features. In the past year or less they have become more social in insanely helpful and kind ways. Not only does Ma.gnolia have groups that you can share bookmarks with but there is the ability to have discussions around the subject in those groups. Sharing with a group is insanely easy. Groups can be private if the manager wishes, which makes it a good test ground for businesses or other organizations to test the social bookmarking waters. I was not a huge fan of rating bookmarks as if I bookmarked something I am wanting to refind it, but in a more social context is has value for others to see the strength of my interest (normall 3 to 5 stars). One of my favorite social features is giving "thanks", which is not a trigger for social gaming like Digg, but is an interpersonal expression of appreciation that really makes Ma.gnolia a friendly and positive social environment.
Started with Beauty, but Now with Ease
Ma.gnolia started as a beautiful del.icio.us (it was not the first) and the beauty got in the way of usability for many. But, Ma.gnolia has kept the beautiful strains and added simple ease of use in a very Apple delightful moments sort of way. The thanks are a nice treat, but the latest interactions that provide non-disruptive ease of use to accomplish a task, without completely taking you away from your previous flow (freaking brilliant in my viewpoint - anything that preserves flow to accomplish a short task is a great step). Another killer feature is Ma.gnolia Roots, which is a bookmarklet that when clicked hovers a semi-transparent layer over the webpage to show information from Ma.gnolia about that page (who has linked to it, tags, annotations, etc.) and makes it really easy to bookmark that page from that screen. The API (including a replica of the del.icio.us API that nearly all services use as the standard), add-ons, Creative Commons license for your bookmarks, many bookmarklet options, and feed options. But, there are also the little things that are not usually seen or noticed, such as great URLs that can be easily parsed, all pages are properly marked up semantically, and Microformats are broadly and properly used throughout the site (nearly at every pivot).
Intelligently Designed
For me Ma.gnolia is not only a great site to look at, a great social bookmarking site that is really social (as well as polite and respectful of my wishes), but a great example for semantic web mark-up (including microformats). There is so much attention to detail in the page markup that for those of us that care it is amazingly beautiful. The visual layer can be optimized for more white space and detail or for much easier scrolling. The interactions, ease of use, and delightful moments that assist you rather than taking you out of your flow (workflow, taskflow, etc.) and make you ask why all applications and social sites are not this wonderful.
Ma.gnolia is not perfect as it needs some tools to better manage and bulk edit your own bookmarks. It could use a sort on search items (as well as narrow by date range). Search could use some RedBull at times. It could improve with filtering by using co-occurance of tag terms as well as for disambiguation.
Overall for me personally, Ma.gnolia is a tool I absolutely love. It took the basic social bookmarking idea in del.icio.us and really made it social. It has added features and functionality that are very helpful and well executed. It is an utter pleasure to use. I can not only share things easily and get the wonderful effects of social interaction, but I can refind things in my now 2,500 plus bookmarks rather easily.
Ma.gnolia Portable Social Networking Group Now Open
I have been talking with people about portable social networks for 18 months or more and initially blogged about it last November (2006) in my post Following Friends Across Walled Gardens. Recently the portable social network effort has flowed into Microformats: Social Network Portability. I have been following Brian Oberkirk's portable social network blog posts and we have had more than a few chats about this in the last few months. Finally it seems that some core geeks are on this quest as well, thanks to a gathering of minds at Foo Camp with Brad Fitzpatrick and David Recordon posting Thoughts on the Social Graph and the starting of the Social Network Portability Google Group. The oauth (more info on OpenAuth). Kevin Lawver has been rocking the real world with his Portable Social Networks at Mashup Camp discussion and example.
Ma.gnolia Portable Social Network Group
Tracking these small bits that are loosely joined needed a little more glue. To this end I started a ma.gnolia group for portable social networking to aggregate links. Already there is a good groups of people joining the group, which is promising. I have been critical of Ma.gnolia in the past, but they have iterated and built a social bookmarking site that has become my favorite social bookmarking service (Clipmarks is my second favorite when I need to just hold onto sub-page items). If you want to keep follow, keep track of the current site, or (even better) contribute bookmarks as well as join in discussion join the group. Ma.gnolia makes joining insanely simple by using OpenID for account creation and login (should you be part of the modern web world - such as having an AOL AIM account).
Open Conversations and Privacy Needs for Business
I thought I would share the latest press bit around this joint, Thomas Vander Wal was quoted in Inc Magazine What's Next: Shout it Out Loud (or in the August 2007 issue beginning on page 69). The article focuses the need and desire for companies to share and be open with more of their data and information. Quite often companies are getting bit by their privacy around what they do (how their source their products/resources, who they donate money to, etc.) and rumors start. It is far more efficient and helpful to be open with that information, as it gets out anyway.
Ironically, in the same paper issue on page 26 there is a an article about When Scandal Knocks..., which includes a story about Jamba Juice and a blog post that inaccurately claimed it had milk in its products, which could have easily been avoided if Jamba Juice had an ingredients listing on its web site.
The Flip Side
There are two flip sides to this. One is the Apple converse, which is a rare example of a company really making a mythic organization out of its privacy. The second is companies really need privacy for some things, but the control of information is often too extreme and is now more harmful than helpful.
Viable Privacy
I have been working on a much longer post looking at the social software/web tools for and in the enterprise. Much of of the extreme openness touted in the new web charge is not a viable reality inside enterprise. There are a myriad of things that need to be private (or still qualify as valid reasons for many). The list include preparations for mergers and acquisitions, securities information dealings (the laws around this are what drive much of the privacy and are out dated), reorganizations (restructuring and layoffs, which organizations that have been open about this have found innovative solutions from the least likely places), personal employee records, as well as contractual reasons (advising or producing products for competitors in the same industry or market segment). Out side of these issues, which normally add up to under 30 to 40% of the whole of the information that flows through an organization, there is a lot of room for openness in-house and to the outside world.
Need for Enterprise Social Tools Grasping Partial Privacy
When we look at the consumer space for social software there are very few consumer tools that grasp social interaction and information sharing on a granular level (Ma.gnolia, Flickr, and the SixApart tools Vox and LiveJournal are the exceptions that always come to mind). But, many of the tools out there that are commonly used as examples of social web tools really fall down when business looks at them and thinks about privacy and selective sociality (small groups). The social web tools all around really need to grow up and improve in this area. As we are seeing the collaboration and social tools evolve to more viable options we start to see their more glaring holes that do not reflect the reality of human social interaction.
Closing the Gap
What we need is for companies to be more open so the marketplace is a more consumer and communicative environment, but we also need our still early social web tools to reflect our social realities that not everything is public and having tools that better fit those needs.
[Cross-posted at Personal InfoCloud: Open Converastions... with comments open on that posting.]
Hoping About
Things have been a wee bit busy the past few weeks. I am off to Banff tomorrow (Monday) and boomerang right back after the WWW Conference Tagging Workshop as I have two days of private workshops in DC just following days.
I am off to the 2007 Identity Workshop for a few days, in part to talk to the some TagCommons people face to face, as well as have some client work to follow-up on. I am then off to south of the boarder, for some work before heading back to the office.
Tagging Workshop at d.construct
I should let you know early that I will be doing a full-day tagging workshop prior to d.construct 2007 in Brighton, England in September. I will post more about this as it is announced. The space is rather limited so keep an eye out.
Workshops Near You & Packages
Those interested in the workshop and I will add you to a list for announcing them. If you would like one in your organization or city I can help get this moving. Toward the end of May I will be providing more information about these, the getting smart packages (workshop or presentation combined with days of advising over a set of months). As I have mentioned these to people the interest is quite strong, so if you want more info on these before they are public on the InfoCloud Solutions site drop me an e-mail.
If you have an e-mail that may have an answer that would be longer than 2 minutes to write I likely still have it lined up, but if you want to jump that line, send the e-mail again (or a series of short e-mails with single questions). I am deeply sorry for my delay in responding. I have no excuse, but the need for more time.
Lessons in Identity
There is much consternation and gnashing of teeth today over the Flickr requiring a Yahoo! login from here forward, it has even made it to the BBC - Flickr to require Yahoo usernames. One of the Flickr co-founders, Stewart Butterfield, provided rationale that would have been a little more helpful up front. The reasons from Stewart are good, but are not solid value propositions for many.
Identity Lessons
There are some insanely important lessons in this dust-up. These lessons revolve around product versus mega-brand/mega-corporation; personal management of identity; and brand trust.
Product Brand versus Mega Brand
One of the primary issues in the Flickr and Yahoo! identity merging involves the love of Flickr the brand and what is stands for in contrast to the perception of the Yahoo!. Flickr was a feisty independent product that innovated the snot out of the web and bent the web to its will to create a better experience for real people. Yahoo is seen as a slow mega corporation that, up until recently, could not sort out how to build for the web beyond 1999. Much of the change in Yahoo is credited to the Flickr team and some others like Bradley Horowitz.
The change in Yahoo! has been really slow as it is a really large company. It seems to be moving in a positive direction with the changes to Yahoo! Mail (came from buying another company who got things right) and the new Yahoo! front door, but the perception still hangs on. Similar to Microsoft's operating system and software, changes to the corporation are like trying to turn a battleship under full steam forward. It is tough changing inertia of a corporation, as not only is it internal technologies and mindsets, but brand perceptions and the hundreds of millions of user perceptions and experience that are going to go through the change.
Take the hulking beast of Yahoo and pair that with a new product and brand Flickr, which is seen as incredibly nimble and innovative and there is a severe clash in perceptions.
Personal Management of Identity
There are a couple issues that are tied up together in the Flickr and Yahoo branding problem involving identity. First, there is the issue of being personally associated with the brand. There are many people who strongly consider themself a "Flickr" person and it is an association with that brand that makes up a part of their personal identity. Many of the "Flickr" people believe they are part of the small lively and innovative new web that Flickr represents. The conflating of the Flickr brand with the Yahoo! brand for many of the "Flickr" people is schizophrenic as the brands are polar opposites of each other. Yahoo! is trying to move toward the Flickr brand appeal and ideals, but again it is turning that battle ship.
The tying one's personal identity to Yahoo! is very difficult for many "Flickr" people. Even within Yahoo! there are battles between the old core Yahoo! and the new upstarts that are changing the way things have always worked. Unfortunately, with the flood of start-up opportunities the Yahoo employees who embrace the new way forward are the people who are seemingly moving out to test the revived waters of web start-ups. This makes turning the battleship all that much harder from the inside.
Second, is managing the digital identity and having personal control over it. Many people really want to control what is known about them by one entity or across an identity. I know many people who have more than one Yahoo! account so to keep different parts of their personal life separate. They keep e-mail separate from search and photos out of their own personal understanding of privacy. Privacy and personal control of digital identity is something that has a wide variation. This required mixing of identity really breaks essential boundary for people who prefer (mildly or strongly) to keep various parts of the digital lives segregated. Many people do not want to have one-stop shopping for their identity and they really want to control who knows what about them. This wish and desire MUST be grasped, understood, and respected.
Brand Trust
All of this leads to people's trust in a brand. People have different levels of trust with different brands (even if the brands are treating their information and privacy in the same manner). Flickr greatly benefited by being a small company who many of the early members knew the founders and/or developers and this personal connection and trust grew through a network effect. The staff at Flickr was and is very attentive to the Flickr community. This personal connection builds trust.
Yahoo! on the other hand is a corporation that has not had a personal touch for many years, but is working to bridge that gap and better connect with its communities around its many products (some of this works well, but much is neglected and the bond is not there). The brand trust is thinner for a larger organization, particularly around privacy and control over digital identity. Many of the large companies make it really difficult to only have one view of your identity turned on when you log in (myYahoo, Mail, and movie ratings are on and all other portions are not logged in - for example).
Conversely, there are those who would like to use their Yahoo! identity and login for things like OpenID login. Recently, Simon Willison (a recent ex-Yahoo) did just this with idproxy.net. And, yet others would like to use other external to Yahoo! logins to be used as a single sign on. Part of this is single sign on and another part is personal control over what digital parts of one's live are connected. It is a personal understanding of trust and a strong belief for many that this perception of trust MUST be respected.
One approach that should NEVER happen is what Google is doing with Dodgeball. This past two weeks I have been contacted by a few people using Dodgeball (I use this service), which was bought and is owned by Google. I was getting contacted by people who found my Dodgeball account by entering my Gmail identity. The problem is I never connected my Gmail to Dodgeball and was going to drop Dodgeball over the required joining of the identities. Google in this instance flat out failed at protecting my identity and privacy, but it does that regularly (personally believe that Google is not Evil, but they are not competent with privacy and identity, which is closely tied with Evil). Had Yahoo! done this with Flickr it would have been really over the top. [I have introduced people at Google to the Digital Identity Gang to better understand digital identity and privacy issues, which is a great sign of them knowing they need to do much better.]
Conclusion
There are a lot of tangents to identity, brand, and personal association that seem to have been left out of the equation in the Yahoo! and Flickr identity merger. A more mature approach to identity at Yahoo! would not have required Flickr members to change over, as for many the changes to value added by conflating the identities is not of interest to those who have not done so yet. For many of those that are feeling hurt it is part of their personal identity that is bruised and broken. Hopefully, Yahoo! has grasped this lesson and will treat other acquisions (Upcoming, del.icio.us, and particularly My Blog Log (among others)) differently.
Ghosts of Technology Past, Present, and Future
The past two days have brought back many memories that have reminded me of the advances in technology as well as the reliance on technology.
Ghost of Rich Web Past
I watched a walk through of a dynamic prototype yesterday that echoed this I was doing in 1999 and 2000. Well, not exactly doing as the then heavy JavaScript would blow up browsers. The DHTML and web interfaces that helped the person using the site to have a better experience quite often caused the browser to lock-up, close with no warning, or lock-up the machine. This was less than 100kb of JavaScript, but many machines more than two years old at that time and with browsers older than a year or two old did not have the power. The processing power was not there, the RAM was not there, the graphics cards were not powerful, and the browsers in need of optimizing.
The demonstration yesterday showed concepts that were nearly the exact concept from my past, but with a really nice interface (one that was not even possible in 1999 or 2000). I was ecstatic with the interface and the excellent job done on the prototype. I realized once again of the technical advances that make rich web interfaces of "Web 2.0" (for lack of a better term) possible. I have seen little new in the world of Ajax or rich interfaces that was not attempted in 2000 or 2001, but now they are viable as many people's machines can now drive this beauties.
I am also reminded of the past technologies as that is what I am running today. All I have at my beck and call is two 667MHz machines. One is an Apple TiBook (with 1 GB of RAM) and one is a Windows machine (killer graphics card with 256MB video RAM and 500MB memory). Both have problems with Amazon and Twitter with their rich interfaces. The sites are really slow and eat many of the relatively few resources I have at my disposal. My browsers are not blowing up, but it feels like they could.
Ghost of Technology Present
The past year or two I have been using my laptop as my outboard memory. More and more I am learning to trust my devices to remind me and keep track of complex projects across many contexts. Once things are in a system I trust they are mostly out of my head.
This experience came to a big bump two days ago when my hard drive crashed. The iterative back-ups were corrupted or faulty (mostly due to a permission issue that would alter me in the middle of the night). The full back-up was delayed as I do not travel with an external drive to do my regular back-ups. My regularly scheduled back-ups seem to trigger when I am on travel. I am now about 2.5 months out from my last good full back-up. I found an e-mail back-up that functioned from about 3 weeks after that last full backup. Ironically, I was in the midst of cleaning up my e-mail for back-up, which is the first step to my major back-up, when the failure happened.
I have a lot of business work that is sitting in the middle of that pile. I also have a lot of new contacts and tasks in the middle of that period. I have my client work saved out, but agreements and new pitches are in the mire of limbo.
Many people are trying to sync and back-up their lives on a regular basis, but the technology is still faulty. So many people have faulty syncing, no matter what technologies they are using. Most people have more than two devices in their life (work and home computer, smart phone, PDA, mobile phone with syncable address book and calendar, iPod, and other assorted options) and the syncing still works best (often passably) between two devices. Now when we start including web services things get really messy as people try to work on-line and off-line across their devices. The technology has not caught up as most devices are marketed and built to solve a problem between two devices and area of information need. The solutions are short sighted.
Ghost of the Technosocial Future
Last week I attended the University of North Carolina Social Software Symposium (UNC SSS) and while much of the conversation was around social software (including tagging/folksonomy) the discussion of technology use crept in. The topic of digital identity was around the edges. The topic of trust, both in people and technology was in the air. These are very important concepts (technology use, digital identity, and trusted technology and trusted people). There is an intersection of the technosocial where people communicate with their devices and through their devices. The technology layer must be understood as to the impact is has on communication. Communication mediated by any technology requires an understanding of how much of the pure signal of communication is lost and warped (it can be modified in a positive manner too when there are disabilities involved).
Our digital communications are improving when we understand the limitations and the capabilities of the technologies involved (be it a web browser of many varied options or mobile phone, etc.). Learning the capabilities of these trusted devices and understanding that they know us and they hold our lives together for us and protect our stuff from peering eyes of others. These trusted devices communicate and share with other trusted devices as well as our trusted services and the people in our lives we trust.
Seeing OpenID in action and work well gave me hope we are getting close on some of these fronts (more on this in another post). Seeing some of the great brains thinking and talking about social software was quite refreshing as well. The ability to build solid systems that augment our lives and bring those near in thought just one click away is here. It is even better than before with the potential for easier interaction, collaboration, and honing of ideas at our doorstep. The ability to build an interface across data sets (stuff I was working on in 1999 that shortened the 3 months to get data on your desk to minutes, even after running analytics and working with a GIS interface) can be done in hours where getting access to the wide variety of information took weeks and months in the past. Getting access to data in our devices to provide location information with those we trust (those we did not trust have had this info for some time and now we can take that back) enables many new services to work on our behalf while protecting our wishes for whom we would like the information shared with. Having trusted devices working together helps heal the fractures in our data losses, while keeping it safe from those we do not wish to have access. The secure transmission of our data between our trusted devices and securely shared with those we trust is quickly arriving.
I am hoping the next time I have a fatal hard drive crash it is not noticeable and the data loss is self-healed by pulling things back together from resources I have trust (well placed trust that is verifiable - hopefully). This is the Personal InfoCloud and its dealing with a Local InfoCloud all securely built with trusted components.
Adding Another SocialNet to Your List of Too Many?
Phil Gyford makes his plea for a single social network sign-on or as it was stated last week by Jeremy Keith on Twitter, "portable social network with XFN".
This post continues at Following Friends Across Walled Gardens at Personal InfoCloud. This covers identity services, Local InfoCloud, trusted friends, and web services. Comments are turned on there.
Technosocial Architect
Those of you that know me well know I am not a fan of being labeled, yes it is rather ironic. A large part of this is a breadth of focus in the lens, from which I view the world. I am deeply interested in how people interact, how people use technology, and the role of information in this equation. My main interest is information and information use, when to people want it and need it, how people acquire it. I am utter fascinated by how technology plays in this mix and how important design is. I look at technology as any mediated form of communication, other than face-to-face communication. The quest began in the technology "quot;paper age" looking at layout and design of text and images on the printed page and the actual and latent messages that were portrayed in this medium. I also dove into television and video as well as computer aided visualizations of data (Tufte was required reading in quantitative methods class (stats) in the early '90s in grad school).
Well, this life long interest only continued when I started digging into the web and online services in the early 90s. But, as my interest turned professional from hobby and grad student my training in quantitative and qualitative (ethnographic) research were used not for public policy, but for understanding what people wanted to do with technology or wished it would work, but more importantly how people wanted to use information in their life.
Basis for Digital Design and Development
As I have waded through web development and design (and its various labels). Most everything I have done is still based on the undergrad training in communication theory and organizational communication. Understanding semantics, rhetoric, layout, design, cogsci, media studies, cultural anthropology, etc. all pay a very important part in how I approach everything. It is a multi-disciplinary approach. In the mid-80s I had figured everybody would be using computers and very adept by the time I finished undergrad, that I thought it was a waste to study computer science as it was going to be like typing and it programming was going to be just like typing, in that everybody was going to be doing (um, a wee bit off on that, but what did I know I was just 18).
People Using Information in Their Life
The one thing that was of deep interest then as it is now, is how people use information in their life and want and need to use information in their life. To many people technology gets in the way of their desired ease of use of information. Those of us who design and build in the digital space spend much of our time looking at how to make our sites and applications easier for people to use.
Do you see the gap?
The gap is huge!
We (as designers and developers) focus on making our technology easy to use and providing a good experience in the domain we control.
People want to use the information when they need it, which is quite often outside the domains we as designers and developers control.
Designing for Information Use and Reuse
Part of what I have been doing in the past few years is looking at the interaction between people and information. With technology we have focussed on findability. Great and good. But, we are failing users on what they do with that information and what they want to do with that information. One question I continually ask people (particularly ones I do not know) is how are you going to use that information. When they are reading or scanning information (paper or digital it does not matter) I ask what is important to them in what is before them. Most often they point to a few things on the page that have different uses (an article referenced in the text, an advertisement for a sale, a quote they really like, etc.). But, the thing that nearly everything that they find important is it has a use beyond what they are reading. They want to read the article that is referenced, they want the date and location for the sale (online address or physical address and date and times), they want to put the quote in a presentation or paper they are writing.
End-to-end is Not the Solution
Many companies try to focus on the end-to-end solution. Think Microsoft or Google and their aim to solve the finding, retaining, using, and reusing of that information all within their products. Currently, the companies are working toward the web as the common interface, but regular people do not live their life on the web, they live it in the physical world. They may have a need for an end-to-end solution, but those have yet to become fully usable. People want to use the tools and technologies that work best for them in various contexts. As designers and developers we can not control that use, but we can make our information more usable and reusable. We have to think of the information as the focal point. We have to think of people actually connecting with other people (that is individuals not crowds) and start to value that person to person interaction and sharing on a massive scale.
Our information and its wrappers must be agnostic, but structured and prepared in a manner that is usable in the forms and applications that people actually use. The information (content to some) is the queen and the people are the king and the marriage of the two of them will continue the reign of informed people. This puts technology and the medium as the serf and workers in that kingdom. Technology and the medium is only the platform for information use and reuse of the information that is in people's lives. That platform, like the foundation of a house or any building must not be noticed and must serve its purpose. It must be simple to get the information and reuse it.
Technology and Design are Secondary
Those of us that live and breathe design and development have to realize what we build is only secondary to what people want. It is the information that is important to regular people. We are only building the system and medium. We are the car and the road that take people to Yosemite where they take pictures, build memories, bond with their travel companions, etc. What is created from this trip to Yosemite will last much longer than the car or road they used to get them to the destination. We only build the conduit. We have to understand that relationship. What we build is transient and will be gone, but what people find and discover in the information they find in what we build must last and live beyond what we control and can build or design. We must focus on what people find and want to use and reuse while they are using what we are designing and building for them.
Information as Building Blocks
All of what is being described is people finding and using information that an other person created and use it in their life. This is communication. It is a social activity. This focus is on building social interactions where information is gathered and used in other contexts. Information use and reuse is part of the human social interaction. This social component with two people or more interacting to communicate must be the focus. We must focus on how that interaction shapes other human interactions or reuses of that information garnered in the communication with an other and ease that interaction. If you are still reading (hello) you probably have something to do with design or development of technology that mediates this communication. We are building social tools in which what is communicated will most likely have a desired use for the people interacting outside of what we have built or designed.
Technosocial Architects
People who understand the social interactions between people and the technologies they use to mediate the interactions need to understand the focus is on the social interactions between people and the relationship that technology plays. It is in a sense being a technosocial architect. I ran across the word technosocial in the writings of Mimi Ito, Howard Rheingold, and Bruce Sterling. It always resonates when I hear technosocial. Social beings communicate and inherent in the term communication is information.
Focus on People, Medium, and Use
Just above you see that I referenced three people (Mimi, Howard, and Bruce) as people who used a term that seems to express how I believe I look at the work I do. It is people, more importantly, it is individuals that I can point to that I trust and listen to and are my social interpreters of the world around me. These people are filters for understanding one facet of the world around me. People have many facets to their life and they have various people (sometimes a collective of people, as in a magazine or newspaper) who are their filters for that facet of their life. There are people we listen to for food recommendations, most likely are different from those that provide entertainment, technology, clothing, auto, child care, house maintenance, finance, etc. We have distinct people we learn to trust over time to provide or reinforce the information we have found or created out of use and reuse of what we have interacted with in our life.
Looking at many of the tools available today there is a focus on the crowd in most social tools on the web. Many regular people I talk to do not find value in that crowd. They want to be able to find individual voices easily that they can learn to trust. Just like I have three people I can point to people in social software environments look at the identity (screen name many times) as their touch point. I really like Ask MetaFilter as a social group "question and answer" tool. Why? Mostly because there are screen names that I have grown to know and trust from years of reading MetaFilter. The medium is an environment that exposes identity (identity is cloaked with a screen name and can be exposed if the person so decides in their profile). People are important to people. In digitally mediated social environments the identity is that point of reference that is a surrogate for name in physical space. In print the name of the writer is important as a means to find or avoid other pieces or works. We do the same in movies, television news, television shows, online videos, podcasts, blogs, etc. the list does not end.
Our social mediums need to keep this identity and surface the identity to build trust. People use identity as gatekeepers in a world of information overload. When I look at Yahoo! Answers and Yahoo! MyWeb (my absolute favorite social bookmarking tool) I get dumped into the ocean of identities that I do not recognize. People are looking for familiarity, particularly familiarity of people (or their surrogate identity). In MyWeb I have a community (unfortunately not one that is faceted) where I trust identities (through a series of past experience) as filters for information in the digital world around us, but I am not placed in this friendly environment, but put in an environment where I find almost nothing I value presented to me. This is the way Yahoo! Answers works as well, but it does not seem like there is the ability to track people who ask or answer questions that a person would find value in.
The tools we use (as well as design and build) must understand the value of person and identity as information filters. The use of information in our lives is one explicit expression of our interest in that subject, the person who created the information, or the source what housed that information. Use and reuse of information is something we need to be able to track to better serve people (this gets in to the area of digital rights management, which usually harms information use more than it enables it, but that is another long essay). The medium needs to understand people and their social interaction people have with the information and the people who create the information and the desired use. This use goes well beyond what we create and develop. Use requires us understanding we need to let go of control of the information so it may be used as people need.
Need for Technosocial Architects
Looking at the digital tools we have around us: websites, social computing services and tools (social networking sites, wikis, blogs, mobile interaction, etc.), portals, intranets, mobile information access, search, recommendation services, personals, shopping, commerce, etc. and each of these is a social communication tool that is based on technology. Each of these has uses for the information beyond the digital walls of their service. Each of these has people who are interacting with other people through digital technology mediation. This goes beyond information architecture, user experience design, interaction design, application development, engineering, etc. It has needs that are more holistic (man I have been trying to avoid that word) and broad as well as deep. It is a need for understanding what is central to human social interactions. It is a need for understanding the technical and digital impact our tools and services have in mediating the social interaction between people. It is a need for understanding how to tie all of this together to best serve people and their need for information that matters to them when they want it and need it.
Is Mechanical Turk for Digital Human Filters?
The New York Times article, Software to Look for Experts Among Your Friends, brought to mind a couple conversations from my recent trip to Amsterdam. At XTech there were a couple presentations about Mechanical Turk (as well as other Amazon web services) and the big question was "what is a killer application for Mechanical Turk?" Many of us through out suggestions, many good, but I have kept thinking about one.
The one killer application is not really a problem a human solves, but the collective interests and amalgamation of information and trained services humans use and have trained. You see, for me Yahoo's MyWeb 2.0 is my killer search solution as it pays attention to what I and my "community" have interest in and mirrors our vocabulary (we used our own vocabulary to tag items of interest on the web in the MyWeb social bookmarking tool). These items of interest in MyWeb 2.0 are offered to me first in my web searches and more often than not what I am seeking is in this collection of mine or my contact's.
These searches that are based on human filters and collaborative filtering of information and structuring what we find of interest and bookmark bringing the information out from 5 to 40 pages deep in the web. It mirrors our interests and perspectives. But, what if we need information outside of our own interests? Now we need not our own corpus of items and possibly one outside those in our loose collective. Let us think I need information about transmission of disease between monkeys. This is not something I have interest in and I am not sure anybody I know (or would be couple of degrees of separation away) would have interest in. This is where I would love to turn to Mechanical Turk to use the filtering and aggregation capabilities of another person's life filtering. I may not want to add the monkey disease transmission to my own corpus, but I need to use a corpus of somebody who has this interest. In a sense I need to uses somebody's digital brain and information attraction mechanisms.
I am not sure if this is really a job for Mechanical Turk, but it requires another person's interests and permission. The Tacit company seems to have a similar product, but only works on Windows and most of the people I would want to tap are not Windows users, but most have web-based information resources.
Odd Moments in the Day - Odd Moments with Technology?
Today brought an odd moment. I looked up at iChat (my IM interface) and I see my name (Thomas Vander Wal) and podcast under Jeremy's name, which means Jeremy is most likely listening to a podcast interview with me. I had never seen that before.
Now I decide to share that odd moment with Jeremy, which I did not realize would cause Jeremy to have an odd moment.
How can the world of pervasive/ubiquitous computing ever get off the ground when we give each other odd moments through our friendly stalking? By the way I prefer using stalking, where as some people like the term monitoring, but the term monitoring does not cause me to think about privacy implications that I believe we must resolve within ourself or learn to better protect our privacy.
The incident today still causes me to chuckle for a short moment then realize how open we are with things on the internet and how different that seems to be even though most of our life has been public, but to a smaller and more localized group. It also resignals that change that came with the internet (well and much of technology) is that we can not see those who can see us. In a town we know the local video store guy knows what we rent, but now Amazon knows what we bought as do those people on our friends list whom we share our purchases with so they can have some insight as what to buy. My local video store guy in San Francisco, near California and 2nd or 3rd Avenue, was amazing. He knew everything I rented in the last few months and would provide perfect recommendations. Did he use a computer to aid himself? Nope, he was just that good and his brain could keep the connection between a face and videos rented and if you liked that video. He knew my taste perfectly and was dead on with recommendations. Not only was he on with me, but most others who frequented his store. He was great recommending, but also could help people avoid movies they did not like.
Was the guy in the video store freaky? Not really, well to me. He was a person and that was his role and his job. I worked in a coffee house for a while first thing in the morning. After a couple months I knew who the first 10 customers would be and I knew about half of the orders or possible variations of what people would order. People are patterned, I could tie the person's face to that pattern for espresso coffee drink order and I could recommend something that they should try. To some this was a little disturbing, but to most is was endearing and was a bond between customer and shopkeeper as I cared enough to know what they would like and remembered them (I did not often remember their names and most of them I did not know their names), but I knew what they drank. If is the familiarity.
So, with technology as an intermediary or as the memory tool what is so freaky? Is it not seeing into somebody's eyes? Is it the magic or somebody more than 3,000 miles away knowing what you are listening to and then have the person whom you are listening to pop-up for a chat? I think it is we have collapsed space and human norms. It is also difficult to judge intent with out seeing face or eyes. I was in a back and forth recently with a friend, but could not sense their intent as it seemed like the tone was harsh (for a person whom I trust quite a bit and think of as being intensely kind and giving) and I finally had to write and ask, but it was written from a point where I was bothered by the tone. My problem was I could not see the eyes of the person and see they playfulness or gestures to know their intent was playful challenging.
While at the Information Architecture Summit a couple/few weeks ago in Vancouver a few of us went to dinner and we played werewolf (my first time playing). But, I was reminded that the eyes hold a lot of information and carry a lot of weight in non-verbal communication. I could pick the werewolf whose eyes I could see, but in two occasions the werewolf was sitting next to me and I could not see their eyes. There was one person in each of the two games whom I did think was the werewolf as their eyes were signaling similarly to people who were not telling the truth in the cultures I grew up in.
Could technology be more easily embraced if it had eyes? Should we have glancing as Matt Webb has suggested and built an application to suggest? But could we take Matt'a concept farther? Would it be helpful?
This was a long post of what was just going to be pointing out an odd moment in the day.
Changing the Flow of the Web and Beyond
In the past few days of being wrapped up in moving this site to a new host and client work, I have come across a couple items that have similar DNA, which also relate to my most recent post on the Come to Me Web over at the Personal InfoCloud.
Sites to Flows
The first item to bring to light is a wonderful presentation, From Sites to Flows: Designing for the Porous Web (3MB PDF), by Even Westvang. The presentation walks through the various activities we do as personal content creators on the web. Part of this fantastic presentation is its focus on microcontent (the granular content objects) and its relevance to context. Personal publishing is more than publishing on the web, it is publishing to content streams, or "flows" as Even states it. These flows of microcontent have been used less in web browsers as their first use, but consumed in syndicated feeds (RDF, RSS/Atom, Trackback, etc.). Even moves to talking about Underskog, a local calendaring portal for Oslo, Norway.
The Publish/Subscribe Decade
Salim Ismail has a post about The Evolution of the Internet, in which he states we are in the Publish/Subscribe Decade. In his explanation Salim writes:
The web has been phenomonally successful and the amount of information available on it is overwhelming. However, (as Bill rightly points out), that information is largely passive - you must look it up with a browser. Clearly the next step in that evolution is for the information to become active and tell you when something happens.
It is this being overwhelmed with information that has been of interest to me for a while. We (the web development community) have built mechanisms for filtering this information. There are many approaches to this filtering, but one of them is the subscription and alert method.
The Come to Me Web
It is almost as if I had written Come to Me Web as a response or extension of what Even and Salim are discussing (the post had been in the works for many weeks and is an longer explanation of a focus I started putting into my presentations in June. This come to me web is something very few are doing and/or doing well in our design and development practices beyond personal content sites (even there it really needs a lot of help in many cases). Focussing on the microcontent chunks (or granular content objects in my personal phraseology) we can not only provide the means for others to best consume our information we are providing, but also aggregate it and provide people with better understanding of the world around them. More importantly we provide the means to best use and reuse the information in people's lives.
Important in this flow of information is to keep the source and identity of the source. Having the ability to get back to the origination point of the content is essential to get more information, original context, and updates. Understanding the identity of the content provider will also help us understand perspective and shadings in the microcontent they have provided.