Off the Top: Folksonomy Entries
Showing posts: 106-120 of 124 total posts
Outside of the 3rd World, Yahoo Buys Flickr
Once again we are back into living in the third world. It is the first day of Spring and we got a lightning storm and out goes the power. We have this to look forward to until Fall. Well, unless we move.
Once the power came on it was errand time, then time shout congratulations to Flickr and Yahoo!. The news was officially announced, that Yahoo! bought Flickr. The Flickr team is staying intact and in Vancouver. Flickr is one of the kick-ass products on the Web right now and with Yahoo! support it could stay at the forefront.
SXSW and Solipsism Presentation
I am having a great time at SXSW Interactive. I am heading back home this evening and will truly miss the remainder of the festival (it truly is a celebration of the web and digital design).
Yesterday I spoke on the panel, How to Leverage Solopsism. My slides for the session focussing on Personal Information Management (1.14MB PDF) is available.
I have has so many wonderful conversations. Please keep in touch and lets keep the conversations going.
Folksonomy: A Wrapper's Delight
As part of the IA Summit 2005 (Montreal) panel on Social Classification (Folksonomies) I presented Folksonomy: A Wrapper's Delight (2.6MB PDF), which refers to the ability to wrap from an emergent vocabulary to a formal controlled vocabulary using a folksonomy. In the discussion I brought up "the flood of information on the internet has turned the scent of information into the stench of information, but folksonomies and other tools help bring back the sweet smell of information". We get the sweet smell from ease of refindability.
Folksonomy Fixed in Wikipedia
It looks like somebody finally fixed Wikipedia entry for Folksonomy, it no longer makes the mistake of calling the a folksonomy a blend of folks and taxonomy. The taxonomy has connotations of being formally structured, which as far from what is going on in del.icio.us from what I see, as the user's of del.icio.us can free tag and choose what ever they wish to tag an object with
Bless you, whom ever fixed this. It looks like it was done today. I have tried to get this fixed before, but my change was bounced, I guess I did not know enough about folksonomies. There is a lot more in the entry that has been added, including the semantic derivation. Thanks to whom ever is getting it right, finally.
This gives me less to complain about Wikipedia than I had before (I have watched entries go from being correct to wrong and stay wrong for quite some time). A co-worker stated Wikipedia is stated to be the current day Hitchhickers Guide to the Galaxy, which was wrong in spots to mortal detriment at times. I somewhat agree, although a little less so today.
Explaining and Showing Broad and Narrow Folksonomies
I have been explaining the broad and narrow folksonomy in e-mail and in comments on others sites, as well as in the media (Wired News). There has still been some confusion, which is very understandable as it is a different concept that goes beyond a simple understanding of tagging. I have put together a couple graphics that should help provide a means to make this distinction some what clearer. The folksonomy is a means for people to tag objects (web pages, photos, videos, podcasts, etc., essentially anything that is internet addressable) using their own vocabulary so that it is easy for them to refind that information again. The folksonomy is most often also social so that others that use the same vocabulary will be able to find the object as well. It is important to note that folksonomies work best when the tags used to describe objects are in the common vocabulary and not what a person perceives others will call it (the tool works like no other for personal information management of information on the web, but is also shared with the world to help others find the information).
Broad Folksonomy
Let's begin with the broad folksonomy, as a tool like del.icio.us delivers. The broad folksonomy has many people tagging the same object and every person can tag the object with their own tags in their own vocabulary. This lends itself very easy to applying the power law curve (power curve) and/or net effect to the results of many people tagging. The power terms and the long tail both work.
The broad folksonomy is illustrated as follows. 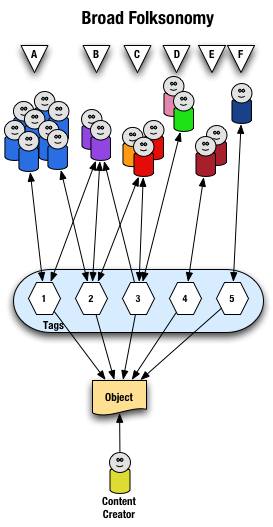
From a high level we see a person creates the object (content) and makes it accessible to others. Other people (groups of people with the same vocabulary represented people blobs and noted with alphabet letters) tag the object (lines with arrows pointing away from the people) with their own terms (represented by numbers). The people also find the information (arrows on lines pointing from the numeric tags back to the people blobs) based on the tags.
Digging a little deeper we see quite a few people (8 people) in group "A" and they have tagged the object with a "1" and a "2" and they use this term to find the object again. Group "B" (2 people) have applied tag "1" and "2" to the object and they use tag terms "1", "2", and "3" to find the information. Group "C" (3 people) have tagged the object with "2" and "3" so that they can find the object. Group "D" has also tagged the object with tag "3" so that they may refind the information this group may have benefitted from the tagging that group "C" provided to help them find the information in the first place. Group "E" (2 people) uses a different term, "4", to tag the object than others before it and uses only this term to find the object. Lastly, group "F" (1 person) uses tag "5" on the object so that they may find it.
Broad Folksonomy and the Power Curve
The broad folksonomy provides a means to see trends in how a broad range are tagging one object. This is an opportunity to see the power law curve at work and show the long-tail.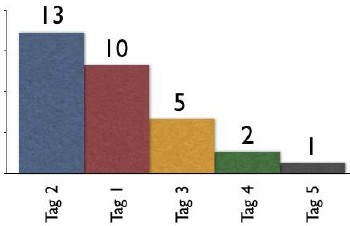
The tags spike with tag "2" getting the largest portion of the tags with 13 entries and tag "1" receiving 10 identical tags. From this point the trends for popular tags are easy to see with the spikes on the left that there are some trends, based on only those that have tagged this object, that could be used extract a controlled vocabulary or at least know what to call the object to have a broad spectrum of people (similar to those that tagged the object, and keep in mind those that tag may not be representative of the whole). We also see those tags out at the right end of the curve, known as the long tail. This is where there is a small minority of people who call the object by a term, but those people tagging this object would allow others with a similar vocabulary mindset to find the object, even if they do not use the terms used by the masses over at the left end of the curve. If we take this example and spread it out over 400 or 1,000 people tagging the same object we will se a similar distribution with even more pronounced spikes and drop-off and a longer tail.
This long tail and power curve are benefits of the broad folksonomy. As we will see the narrow folksonomy does not have the same properties, but it will have benefits. These benefits are non-existent for those just simply tagging items, most often done by the content creator for their own content, as is the means Technorati has done, even with their following tag links to destinations other than Technorati (as they initially had laid out). The benefits of the long tail and power curve come from the richness provided by many people openly tagging the same object.
Narrow Folksonomy
The narrow folksonomy, which a tool like Flickr represents, provides benefit in tagging objects that are not easily searchable or have no other means of using text to describe or find the object. The narrow folksonomy is done by one or a few people providing tags that the person uses to get back to that information. The tags, unlike in the broad folksonomy, are singular in nature (only one tag with the term is used as compared to 13 people in the broad folksonomy using the same tag). Often in the narrow folksonomy the person creating the object is providing one or more of the tags to get things started. The goals and uses of the narrow folksonomy are different than the broad, but still very helpful as more than one person can describe the one object. In the narrow the tags are directly associated with the object. Also with the narrow there is little way of really knowing how the tags are consumed or what portion of the people using the object would call it what, therefore it is not quite as helpful as finding emerging vocabulary or emergent descriptions. We do find that tags used to describe are also used for grouping, which is particularly visible and relevant in Flickr (this is also done in broad folksonomies, but currently not to the degree of visibility that it is done on Flickr, which may be part of the killer interactive environment Ludicorp has created for Flickr).
The narrow folksonomy is illustrated as follows.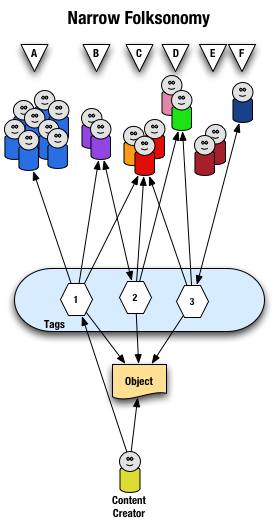
From a high level we see a person creates the object and applies a tag ("1") that represents what they call the object or believe describes the object. There are fewer tags provided than in a broad folksonomy and there is only one of each tag applied to the object. The consumers of the object also can apply tags that help them find the object or describe what they believe are the terms used to describe this object.
A closer look at the interaction between people and the object and tags in a narrow folksonomy shows us that group "A" uses tag "1" to find and come back to the object (did the creator do this on purpose? or did she just tag it with what was helpful to her). We see group "B" also using tag "1" to find the object, but they have tagged the object with tag "2" to also use as a means to find the object. Group "C" uses tag "1","2", and "3" to find the object and we also note this group did not apply any of its own tags to the object as so is only a consumer of the existing folksonomy. We see group "D" uses tags "2" and "3" to find the objects and it too does not add any tags. Group "E" is not able to find the object by using tags as the vocabulary it is using does not match any of the tags currently provided. Lastly, group "F" has their own tag for the object that they alone use to get back to the object. Group "F" did not find the object through existing tags, but may have found the object through other means, like a friend e-mailed them a link or the object was included in a group they subscribe to in their feed aggregator.
We see that the richness of the broad folksonomy is not quite there in a narrow folksonomy, but the folksonomy does add quite a bit of value. The value, as in the case of Flickr, is in text tags being applied to objects that were not findable using search or other text related tools that comprise much of how we find things on the internet today. The narrow folksonomy does provide various audiences the means to add tags in their own vocabulary that will help them and those like them to find the objects at a later time. We are much better off with folksonomies than we were with out them, even if it is a narrow folksonomy being used.
Conclusion
We benefit from folksonomies as the both the personal vocabulary and the social aspects help people to find and retain a tether to objects on the web that are an interest to them. Who is doing the tagging is important to understand and how the tags are consumed is an important factor. This also helps us see that not all tagging is a folksonomy, but is just tagging. Tagging in and of its self is a helpful step up from no tagging, but is no where near as beneficial as opening the tagging to all. Folksonomy tagging can provide connections across cultures and disciplines (an knowledge management consultant can find valuable information from an information architect because one object is tagged by both communities using their own differing terms of practice). Folksonomy tagging also makes up for missing terms in a site's own categorization system/taxonomy. This hopefully has made things a little clearer for all in our understanding the types of folksonomies and tagging and the benefits that can be derived.
This entry first appeared at Personal InfoCloud and comments are open for your use there.
It is Speaking Season
The next month or so has a few speaking engagements lined up. They are as follows:
Date: February 17th 2005 - Thursday (9am to 11:30am)
Event: The Web Mangers Roundtable
Topic: Blogging into 2005 panel (with Mike Lee of AARP and Lee Rainey of PEW Foundation
Location: Washington, DC, USA
Access: Sold Out
Date: March 5th 2005 - Saturday (10:30am - 12:15pm)
Event: ASIS&T Information Architecture Summit
Topic: Sorting Out Classification - with Stewart Butterfield, Peter Merholz, Peter Morville, and Gene Smith
Location: Montreal, Quebec, Canada
Access: IA Summit Registration
Date: March 5th 2005 - Saturday (4pm to 4:45pm)
Event: ASIS&T Information Architecture Summit
Topic: IA for the Personal InfoCloud
Location: Montreal, Quebec, Canada
Access: IA Summit Registration
Date: March 9th 2005 - 6:30pm
Event: ASIS&T Potomac Valley Chapter Panel
Topic: From Soup to Nuts: Blogs, Blogging, and the Greater Impacts to Information Science -p with James Melzer of SRA International and Christina Pikas of Johns Hopkins University
Location: Laurel, MD, USA: Campus of Johns Hopkins Applied Physics Laboratory
Access: Registration Form
Date: March 14th (?), 2005 (Specifics to follow)
Event: South by Southwest Interactive Festival
Topic: How to Leverage Solipsism - with Peter Merholz and Stewart Butterfield
Location: Austin, TX, USA
Access: SXSW Interactive Registration
Personal InfoCloud has a Real Home
We finally (yes, finally) have Personal InfoCloud ( http://www.personalinfocloud.com ) up and running. This has been a long time coming. Items posted there will most likely be cross-posted here as well. The Personal InfoCloud will takes its place with some other things that are on their way in the next few months.
Personal InfoCloud (PIC) will be home to discussions around the PIC and related topics. More than likely folksonomy discussions will move there as they are a subset of the Personal InfoCloud. This will become clearer in relatively short order, but folksonomy allows people to track information they have previously found using their own organization and vocabulary. Personal organization of information using one's own vocabulary is central to the Personal InfoCloud. Nearly a year ago I started using Flickr as an example of a site building for the PIC.
Enjoy the new site. Yes, now that the domain is attached we will be posting to it more often.
Granular Social Networks to the Rescue
Things have been buzzing around these parts on the folksonomy subject. A few weeks ago I started thinking about social networks (Feedster, Orkut, and LinkedIn) and why they do not work, well other than LinkedIn I do not find much if any useful value. I do think there can be value in social networks and actually believe we will need social networks in the not too distant future.
Why will we need social networks? As personal electronic information publication continues to grow we have more opportunities for shared information that has value for us. The problem will be there will be even more of a deluge of information than there is today when we go seeking information. As people start annotating physical space and tagging physical space we will need the means to quickly parse through the information to find that information that may be the most valuable to us.
Consider standing in front of a restaurant in a city that is new to us. We are considering the menu and look to our mobile phone to see what others have said about the restaurant and there are more than 200 reviews and comments, which is far too many to be read on a mobile phone or even parsed on a mobile phone. But, before we request the reviews and comments our mobile device as noted our location and pushed that out to our predictive services in our Personal InfoCloud (looking at our own reviews, preferences (food and restaurants in this case), and contacts), and checks our social network based on food and restaurant interests. Our phone returns the top 3 reviews and comments that should be of value to us and two of these reviews are three and four degrees from us (could go even farther) in our social network, but based on our food preferences and our trust of our friend s taste in food and restaurants and their service and their friend's same values, and so on. The other review is one who is considered to be the polar opposite of our preferences and can be used to shade our interest.
How did we get to a social network that has needed value? If we take the same folksonomy approach and apply it to social networks we could see social network tools that actually have value. This would work as a narrow folksonomy (like Flickr) with a person tagging people with the connections they trust (or even those they do not trust with a "-" prefix).
The folksonomy is just one option, but social networks have to get far more granular than the broad line that is drawn between people today.
Technorati Opens Spam Tagging - Updated
The talk this past week was all about Technorati and their tagging tool, but the tool offers very little value and may be an incubator for spam more than a folksonomy tool.
Where del.icio.us gets folksonomy right (I know this is reflexive) by having many people tag online objects, Technorati gets folksonomy backwards with one user spitting tags into an aggregator. The only link I would trust in Technorati's tool is one that I also found on del.icio.us.
Why so harsh? Technorati has created a tool not from social interaction and using the internet to build value through the network effect (Technorati made the power curve popular, which is the visualization of the net effect). Technorati has no moderating the content that can be dumped in my any slimy spammer that now has a ripe new target. Lacking moderation and any socially derived checks to the system I am quite disappointed with Technorati and this effort.
I use Technorati keywords to track things I have an interest in and their tool does a great job pulling in information (I also use Feedster for the same purpose) and find it to be the top of its class in this effort.
Updated
Eric Scheid provides an excellent suggestion, which made me realize it is easy for Technorati to get it right and much of my problem was the links went in the wrong direction. Eric states...
I have a suggestion for another link format for "technorati" tags which would turn things around ... it would look like this:
<a href="http://whatever.bloghost.com/page/etc" rel="tag.TAGNAME1 tag.TAGNAME2">descriptive text for the link</a>This way I can tag the pages I *link* to, and not just the pages I publish.
I'm also able to assign multiple tags to the linked page, and of course since other people could well be linking to that same page they can apply their own tags too. Think of the social tagging nature of del.icio.us without the intermediary of del.icio.us.
All we need is the "tag." prefix to identify the tagging relationship, as distinct from other relationship types (eg. vote-for, XFN, the usual W3C things, etc).
Yes, this modification would make Technorati tags a true folksonomy. Will they fix it to get it right?
Folksonomy Explanations
The past few weeks have seen my inbox flooded with folksonomy questions. I am going to make things easier on my inbox by posting some common discussions here. Many of the items I am posting I have posted else where, but this will also be a great help for me.
There have been many people who have correctly discerned a difference between the two prime folksonomy examples, Flickr and del.icio.us. As I first stated in a comment to Clay Shirky's first article on Folksonomy, there are two derivations of folksonomy. There is a narrow folksonomy and a broad folksonomy. On August 26th I stated...
Clay, you bring in some very good points, particularly with the semantic differences of the terms film, movie, and cinema, which defy normalization. A broad folksonomy, like del.icio.us, allows for many layers of tagging. These many layers develop patterns of consistency (whether they are right or wrong in a professional's view is another matter, but that is what "the people" are calling things). These patterns eventually develop quasi power law for around the folk understanding of the terms as they relate to items.
Combining the power tags of "skateboarding, tricks, movie " (as you point out) will get to the desired information. The hard work of building a hierarchy is not truly essential, but a good tool that provides ease of use to tie the semantic tags is increasingly essential. This is a nascent example of a semantic web. What is really nice is the ability to use not only the power tags, but also the meta-noise (the tags that are not dominant, but add semantic understanding within a community). In the skateboarding example a meta-noise tag could be gnarly that has resonance in the skate community and adds another layer of refinement for them.
The narrow-folksonomy, where one or few users supply the tags for information, such as Flickr, does not supply power tags as easily. One or few people tagging one relatively narrowly distributed item makes normalizing more difficult to employ an tool that aggregates terms. This situation seems to require a tool up front that prompts the individuals creating the tags to add other, possibly, related tags to enhance the findability of the item. This could be a tool that pops up as the user is entering their tags that asks, "I see you entered mac do you want to add fruit, computer, artist, raincoat, macintosh, apple, friend, designer, hamburger, cosmetics, retail, daddy tag(s)?"
This same distinction is brought up on IAWiki' Folksonomy entry.
Since this time Flickr has added the ability for friends and family (and possibly contacts) to add tags, which gives Flickr a broader folksonomy. But, the focus point is still one object that is being tagged, where as del.icio.us has many people tagging one object. The broad-folksonomy is where much of the social benefit can be derived as synonyms and cross-discipline and cross-cultural vocabularies can be discovered. Flickr has an advantage in providing the individual the means to tag objects, which makes it easier for the object to get found.
This brings to the forefront the questions about Google's Gmail, which allows one person the ability to freely tag their e-mail entries. Is Gmail using a folksonomy? Since Gmail was included in the grouping of on-line tools that were in the discussion of what to call these things (along with Flickr and del.icio.us) when folksonomy was coined I say yes. But, my belief that Gmail uses a folksonomy (regular people's categorization through tagging) relates to it using the same means of one person adding tags so that object can be found by them. This is identical to how people tag in Flickr (as proven by the self-referential "me" that is ever prevalent) and del.icio.us. People tag in their own vocabulary for their own retrieval, but they also will tag for social context as well, such as Flickr's "MacWorld" tags. In this case Wikipedia is a little wrong and needs improving.
I suppose Gmail would be a personal folksonomy to the Flickr narrow folksonomy and the del.icio.us broad folksonomy. There are distinct futures for all three folkonomies to grow. Gmail is just the beginning of personal tagging of digital objects (and physical objects tagged with digital information). Lou Rosenfeld hit the nail on the head when he stated, "I'm not certain that the product of folksonomy development will have much long term value on their own, I'll bet dollars to donuts that the process of introducing a broader public to the act of developing and applying metadata will be incredibly invaluable.". These tools, including Gmail, are training for understanding metadata. People will learn new skills if they have a perceived greater value (this is why millions of people learned Palm's Graffiti as they found a benefit in learning the script).
Everybody has immense trouble finding information in their hierarchal folders on their hard drive. Documents and digital objects have more than one meaning than the one folder/directory, in which they reside. Sure there are short cuts, but tracking down and maintaining shortcuts is insanely awkward. Tags will be the step to the next generation of personal information managment.
San Francisco Bound
I will be in San Francisco and surounding Bay Area on the 20th and 21st of January. There are many folks I would like to hang and chat with. I have been swamped with a handful of things the past couple weeks, along with a huge flood of spam mail (I think I have spam abated for the moment). Interested in talking blogs, folksonomy, Personal InfoCloud, Model of Attraction, mobile, interaction design, Web Standards, etc. please drop a note. Thursday evening may be the best option at the moment. Use the contact link above (needs JavaScript on) or send to thomas at this domain.
From Tags to the Future
Merlin hit on something in his I Want a Pony: Snapshots of a Dream Productivity App where he discusses:
Tags - People have strong feelings about metadata and the smart money is usually against letting The User apply his or her own tags and titles for important shared data ("They do it wrong or not at all," the burghers moan). But things are changing for personal users. Two examples? iTunes and del.icio.us. Nobody cares what "metadata" means, but they for damn sure know they want their mp3s tagged correctly. Ditto for del.icio.us, where Master Joshua has shown the world that people will tag stuff that’s important in their world. Don't like someone else's homebrewed taxonomy? Doesn't matter, because you don't need to like it. If I have a repeatable system for tagging the information on just my Mac and it's working for me, that's really all that matters. I would definitley love that tagging ability for the most atomic piece of any work and personal information I touch.
This crossed my radar the same time as I read Jeff Hawkins' discussion about how he came up with Graffiti for Palm devices. He noticed people did not find touch typing intuitive, but they saw the benefit of it and it worked. Conversely in the early 90s people were interacting with handwriting interpreters that often did not understand one's own handwriting. Jeff came up with something that would give good results with a little bit of effort put in. Palm and Graffiti took off. (Personally, I was lucky when I got my first Palm, in that I was on the west coast and waking on east coast time, which gave me two or three hours of time to learn Graffiti before anybody else was awake. It only took two or three days to have it down perfectly).
Merlin's observation fits within these parameters. Where people have not cared at all about metadata they have learned to understand the value of good tags and often do so in a short period of time. iTunes really drives the value of proper tagging home to many (Napster and other shared music environments brought to light tagging to large segments of the population). In a sense folksonomies of del.icio.us and Flickr are decedents of the shared music environments. People could see that tagged objects, whose tags to be edited and leveraged had value in one's ability to find what one is looking for based on those tags.
As the web grew up on deep linking and open environments to find and share information. So to will tagging become that mantra for the masses. All objects, both digital and physical, will be tagged to provide immediacy of information access so to gain knowledge. Learning to search, parse, filter, and leverage predictive tools (ones that understand the person's desires, context, situation, and frame of reference so to quickly (if not instantly) gather, interpret, and make aware the information around the person). Should the person be late for a meeting their predictive filters are going to limit all be the required information, possibly a traffic jam on their normal route as well as their option A route. A person that has some free time may turn up the serendipity impact and get exposed to information they may normally have filtered out of their attention. The key will be understanding tags have value and just as metadata for other objects, like e-mail subject lines, can be erroneous and indicators of spam, our life filters will need the same or similar. We will want to attract information to us that we desire and will need to make smart and informed choices and tags are just one of the means to this end.
Flickr and the Future of the Internet
Peter's post on Flickr Wondering triggers some thoughts that have been gelling for a while, not only about what is good about Flickr, but what is missing on the internet as we try to move forward to mobile use, building for the Personal InfoCloud (allowing the user to better keep information the like attracted to them and find related information), and embracing Ubicomp. What follows is my response to Peter's posting, which I posted here so I could keep better track of it. E-mail feedback is welcome. Enjoy...
You seemed to have hit on the right blend of ideas to bring together. It is Lane's picture component and it is Nadav's integration of play. Flickr is a wonderfully written interactive tool that adds to photo managing and photo sharing in ways that are very easy and seemingly intuitive. The navigations is wonderful (although there are a few tweak that could put it over the top) and the integration of presentational elements (HTML and Flash) is probably the best on the web as they really seem to be the first to understand how to use which tools for what each does best. This leads to an interface that seems quick and responsive and works wonderfully in the hands of many. It does not function perfectly across platforms, yet, but using the open API it is completely possible that it can and will be done in short order. Imagine pulling your favorites or your own gallery onto your mobile device to show to others or just entertain yourself.
Flickr not only has done this phenomenally well, but may have tipped the scales in a couple of areas that are important for the web to move forward. One area is an easy tool to extract a person's vocabulary for what they call things. The other is a social network that makes sense.
First, the easy tool for people to add metadata in their own vocabulary for objects. One of the hinderances of digital environments is the lack of tools to find objects that do not contain words the people seeking them need to make the connection to that object they are desiring. Photos, movies, and audio files have no or limited inherent properties for text searching nor associated metadata. Flickr provides a tool that does this easily, but more importantly shows the importance of the addition of metadata as part of the benefit of the product, which seems to provide incentive to add metadata. Flickr is not the first to go down this path, but it does it in a manner that is light years ahead of nearly all that came before it. The only tools that have come close is HTML and Hyperlinks pointing to these objects, which is not as easy nor intuitive for normal folks as is Flickr. The web moving forward needs to leverage metadata tools that add text addressable means of finding objects.
Second, is the social network. This is a secondary draw to Flickr for many, but it is one that really seems to keep people coming back. It has a high level of attraction for people. Part of this is Flickr actually has a stated reason for being (web-based photo sharing and photo organizing tool), which few of the other social network tools really have (other than Amazon's shared Wish Lists and Linkedin). Flickr has modern life need solved with the ability to store, manage, access, and selectively share ones digital assets (there are many life needs and very few products aim to provide a solution for these life needs or aims to provide such ease of use). The social network component is extremely valuable. I am not sure that Flickr is the best, nor are they the first, but they have made it an easy added value.
Why is social network important? Helping to reduct the coming stench of information that is resultant of the over abundance of information in our digital flow. Sifting through the voluminous seas of bytes needs tools that provide some sorting using predictive methods. Amazon's ratings and that matching to other's similar patterns as well as those we claim as our friends, family, mentors, etc. will be very important in helping tools predict which information gets our initial attention.
As physical space gets annotated with digital layers we will need some means of quickly sorting through the pile of bytes at the location to get a handful that we can skim through. What better tool than one that leverages our social networks. These networks much get much better than they are currently, possibly using broader categories or tags for our personal relationships as well as means of better ranking extended relationships of others as with some people we consider friends we do not have to go far in their group of friends before we run into those who we really do not want to consider relevant in our life structures.
Flickr is showing itself to be a popular tool that has the right elements in place and the right elements done well (or at least well enough) to begin to show the way through the next steps of the web. Flickr is well designed on many levels and hopefully will not only reap the rewards, but also provide inspiration to guide more web-based tools to start getting things right.
Salon Writes Story on Flickr
Salon's Katharine Mieszkowski did a story on Flickr that captures what is really good about Flickr. She even, appropriately, includes folksonomy in the write-up.
Would We Create Hierarchies in a Computing Age?
Lou has posted my question:
Is hierarchy a means to classify and structure based on the tools available at the time (our minds)? Would we have structured things differently if we had computers from the beginning?
Hierarchy is a relatively easy means of classifying information, but only if people are familiar with the culture and topic of the item. We know there are problems with hierarchy and classification across disciplines and cultures and we know that items have many more attributes that which provide a means of classification. Think classification of animals, is it fish, mammal, reptile, etc.? It is a dolphin. Well what type of dolphin, as there are some that are mammal and some that are fish? Knowing that the dolphin swims in water does not help the matter at all in this case. It all depends on the context and the purpose.
Hierarchy and classification work well in limited domains. In the wild things are more difficult. On the web when we are building a site we often try to set hierarchies based on the intended or expected users of the information. But the web is open to anybody and outside the site anybody can link to any thing they wish that is on the web and addressable. The naming for the hyperlink can be whatever helps the person creating the link understand what that link is pointing to. This is the initial folksonomy, hyperlinks. Google was smart in using the link names in their algorithm for helping people find information they are seeking. Yes, people can disrupt the system with Googlebombing, but the it just takes a slightly smarter tool to get around these problems.
You see hierarchies are simple means of structuring information, but the world is not as neat nor simple. Things are far more complex and each person has their own derived means of structuring information in their memory that works for them. Some have been enculturated with scientific naming conventions, while others have not.
I have spent the last few years watching users of a site not understand some of the hierarchies developed as there are more than the one or two user-types that have found use in the information being provided. They can get to the information from search, but are lost in the hierarchies as the structure is foreign to them.
It is from this context that I asked the question. We are seeing new tools that allow for regular people to tag information objects with terms that these people would use to describe the object. We see tools that can help make sense of these tags in a manner that gets other people to information that is helpful to them. These folksonomy tools, like Flickr, del.icio.us, and Google (search and Gmail) provide the means to tame the whole in a manner that is addressable across cultures (including nationalities and language) and disciplines. This breadth is not easily achievable by hierarchies.
So looking back, would we build hierarchies given today's tools? Knowing the world is very complex and diverse do simple hierarchies make sense?