Off the Top: Metadata Entries
The Data Journalism Handbook is Available
The Data Journalism Handbook is finally available online and soon as the book Data Journalism Handbook - from Amazon or The Data Journalism Handbook - from O’Reilly, which is quite exciting. Why you ask?
In the October of 2010 the Guardian in the UK posted a Data Journalism How To Guide that was fantastic. This was a great resource not only for data journalists, but for anybody who has interest in finding, gathering, assessing, and doing something with the data that is shared found in the world around us. These skill are not the sort of thing that many of us grew up with nor learned in school, nor are taught in most schools today (that is another giant problem). This tutorial taught me a few things that have been of great benefit and filled in gaps I had in my tool bag that was still mostly rusty and built using the tool set I picked up in the mid-90s in grad school in public policy analysis.
In the Fall of 2011 at MozFest in London many data journalist and others of like mind got together to share their knowledge. Out of this gathering was the realization and starting point for the handbook. Journalists are not typically those who have the deep data skills, but if they can learn (not a huge mound to climb) and have it made sensible and relatively easy in bite sized chunk the journalists will be better off.
All of us can benefit from this book in our own hands. Getting to the basics of how gather and think through data and the questions around it, all the way through how to graphically display that data is incredibly beneficial. I know many people who have contributed to this Handbook and think the world of their contributions. Skimming through the version that is one the web I can quickly see this is going to be an essential reference for all, not just journalists, nor bloggers, but for everybody. This could and likely should be the book used in classes in high schools and university information essentials taught first semester first year.
As If Had Read
The idea of a tag "As If Had Read" started as a riff off of riffs with David Weinberger at Reboot 2008 regarding the "to read" tag that is prevalent in many social bookmarking sites. But, the "as if had read" is not as tongue-in-cheek at the moment, but is a moment of ah ha!
I have been using DevonThink on my Mac for 5 or more years. It is a document, note, web page, and general content catch all that is easily searched. But, it also pulls out relevance to other items that it sees as relevant. The connections it makes are often quite impressive.
My Info Churning Patterns
I have promised for quite a few years that I would write-up how I work through my inbound content. This process changes a lot, but it is back to a settled state again (mostly). Going back 10 years or more I would go through my links page and check all of the links on it (it was 75 to 100 links at that point) to see if there was something new or of interest.
But, that changed to using a feedreader (I used and am back to using Net News Wire on Mac as it has the features I love and it is fast and I can skim 4x to 5x the content I can in Google Reader (interface and design matters)) to pull in 400 or more RSS feeds that I would triage. I would skim the new (bold) titles and skim the content in the reader, if it was of potential interest I open the link into a browser tab in the background and just churn through the skimming of the 1,000 to 1,400 new items each night. Then I would open the browser to read the tabs. At this stage I actually read the content and if part way through it I don't think it has current or future value I close the tab. But, in about 90 minutes I could triage through 1,200 to 1,400 new RSS feed items, get 30 to 70 potential items of value open in tabs in a browser, and get this down to a usual 5 to 12 items of current or future value. Yes, in 90 minutes (keeping focus to sort the out the chaff is essential). But, from this point I would blog or at least put these items into Delicious and/or Ma.gnolia or Yahoo MyWeb 2.0 (this service was insanely amazing and was years ahead of its time and I will write-up its value).
The volume and tools have changed over time. Today the same number of feeds (approximately 400) turn out 500 to 800 new items each day. I now post less to Delicious and opt for DevonThink for 25 to 40 items each day. I stopped using DevonThink (DT) and opted for Yojimbo and then Together.app as they had tagging and I could add my context (I found my own context had more value than DevonThink's contextual relevance engine). But, when DevonThink added tagging it became an optimal service and I added my archives from Together and now use DT a lot.
Relevance of As if Had Read
But, one of the things I have been finding is I can not only search within the content of items in DT, but I can quickly aggregate related items by tag (work projects, long writing projects, etc.). But, its incredible value is how it has changed my information triage and process. I am now taking those 30 to 40 tabs and doing a more in depth read, but only rarely reading the full content, unless it is current value is high or the content is compelling. I am acting on the content more quickly and putting it into DT. When I need to recall information I use the search to find content and then pull related content closer. I not only have the item I was seeking, but have other related content that adds depth and breath to a subject. My own personal recall of the content is enough to start a search that will find what I was seeking with relative ease. But, were I did a deeper skim read in the past I will now do a deeper read of the prime focus. My augmented recall with the brilliance of DevonThink works just as well as if I had read the content deeply the first time.
Social Design for the Enterprise Workshop in Washington, DC Area
I am finally bringing workshop to my home base, the Washington, DC area. I am putting on a my Social Design for the Enterprise half-day workshop on the afternoon of July 17th at Viget Labs (register from this prior link).
Yes, it is a Friday in the Summer in Washington, DC area. This is the filter to sort out who really wants to improve what they offer and how successful they want their products and solutions to be.
Past Attendees have Said...
A few hours and a few hundred dollar saved us tens of thousands, if not well into six figures dollars of value through improving our understanding (Global insurance company intranet director)
From an in-house workshop
We are only an hour in, can we stop? We need to get many more people here to hear this as we have been on the wrong path as an organization (National consumer service provider)
Can you let us know when you give this again as we need our [big consulting firm] here, they need to hear that this is the path and focus we need (Fortune 100 company senior manager for collaboration platforms)
In the last 15 minutes what you walked us through helped us understand a problem we have had for 2 years and a provided manner to think about it in a way we can finally move forward and solve it (CEO social tool product company)
Is the Workshop Only for Designers?
No, the workshop is aimed at a broad audience. The focus of the workshop gets beyond the tools features and functionality to provide understanding of the other elements that make a giant difference in adoption, use, and value derived by people using and the system owners.
The workshop is for user experience designers (information architects, interaction designers, social interaction designers, etc.), developers, product managers, buyers, implementers, and those with social tools running already running.
Not Only for Enterprise
This workshop with address problems for designing social tools for much better adoption in the enterprise (in-house use in business, government, & non-profit), but web facing social tools.
The Workshop will Address
Designing for social comfort requires understanding how people interact in a non-mediated environment and what realities that we know from that understanding must we include in our design and development for use and adoption of our digital social tools if we want optimal adoption and use.
- Tools do not need to be constrained by accepting the 1-9-90 myth.
- Understanding the social build order and how to use that to identify gaps that need design solutions
- Social comfort as a key component
- Matrix of Perception to better understanding who the use types are and how deeply the use the tool so to build to their needs and delivering much greater value for them, which leads to improved use and adoption
- Using the for elements for enterprise social tool success (as well as web facing) to better understand where and how to focus understanding gaps and needs for improvement.
- Ways user experience design can be implemented to increase adoption, use, and value
- How social design needs are different from Web 2.0 and what Web 2.0 could improve with this understanding
More info...
For more information and registration to to Viget Lab's Social Design for the Enterprise page.
I look forward to seeing you there.
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-idÃ67bb8b-4652-46bc-bc0d-996c1a2d5205)
Catching Up On Personal InfoCloud Blog Posts
Things here are a little quiet as I have been in writing mode as well as pitching new work. I have been blogging work related items over at Personal InfoCloud, but I am likely only going to be posting summaries of those pieces here from now on, rather than the full posts. I am doing this to concentrate work related posts, particularly on a platform that has commenting available. I am still running my own blogging tool here at vanderwal.net I wrote in 2001 and turned off the comments in 2006 after growing tired of dealing comment spam.
The following are recently posted over at Personal InfoCloud
SharePoint 2007: Gateway Drug to Enterprise Social Tools
SharePoint 2007: Gateway Drug to Enterprise Social Tools focusses on the myriad of discussions I have had with clients of mine, potential clients, and others from organizations sharing their views and frustrations with Microsoft SharePoint as a means to bring solid social software into the workplace. This post has been brewing for about two years and is now finally posted.
Optimizing Tagging UI for People & Search
Optimizing Tagging UI for People and Search focuses on the lessons learned and usability research myself and others have done on the various input interfaces for tagging, particularly tagging with using multi-term tags (tags with more than one word). The popular tools have inhibited adoption of tagging with poor tagging interaction design and poor patterns for humans entering tags that make sense to themselves as humans.
LinkedIn: Social Interaction Design Lessons Learned (not to follow)
I have a two part post on LinkedIn's social interaction design. LinkedIn: Social Interaction Design Lessons Learned (not to follow) - 1 of 2 looks at what LinkedIn has done well in the past and had built on top. Many people have expressed the new social interactions on LinkedIn have decreased the value of the service for them.
The second part, LinkedIn: Social Interaction Design Lessons Learned (not to follow) - 2 of 2 looks at the social interaction that has been added to LinkedIn in the last 18 months or so and what lessons have we as users of the service who pay attention to social interaction design have learned. This piece also list ways forward from what is in place currently.
A Stale State of Tagging?
David Weinberger posted a comment about Tagging like it was 2002, which quotes Matt Mower discussing the state of tagging. I mostly agree, but not completely. In the consumer space thing have been stagnant for a while, but in the enterprise space there is some good forward movement and some innovation taking place. But, let me break down a bit of what has gone on in the consumer space.
History of Tagging
The history of tagging in the consumer space is a much deeper and older topic than most have thought. One of the first consumer products to include tagging or annotations was the Lotus Magellan product, which appeared in 1988 and allowed annotations of documents and objects on one's hard drive to ease finding and refinding the them (it was a full text search which was remarkably fast for its day). By the mid-90s Compuserve had tagging for objects uploaded into its forum libraries. In 2001 Bitzi allowed tagging of any media what had a URL.
The down side of this tagging was the it did not capture identity and assuming every person uses words (tag terms) in the same manner is a quick trip to the tag dump where tags are not fully useful. In 2003 Joshua Schacter showed the way with del.icio.us that not only allowed identity, upon which we can disambiguate, but it also had a set object in common with all those identities tagging it. The common object being annotated allows for a beginning point to discern similarity of identityĵs tag terms. Part of this has been driven on Joshua's focus on the person consuming the content and allowing a means for that consumer to get back to their information and objects of interest. (It is around this concept that folksonomy was coined to separate it from the content publisher tagging and non-identity related tagging.) This picked up on the tagging for one's self that was in Lotus Magellan and brings it forward to the web.
Valuable Tagging
It was in del.icio.us that we saw tagging that really did not work well in the past begin to become valuable as the clarity in tag terms that was missing in most all other tagging systems was corrected for in the use of a common object being tagged and the identity of the tagger. This set the foundation for some great things to happen, but have great things happened?
Tagging Future Promise
Del.icio.us set many of out minds a flutter with insight into the dreams of the capability of tagging having a good foothold with proper structure under them. A brilliant next step was made by RawSugar (now gone) to use this structure to make ease of disambiguating the tag terms (by appleseed did you mean: Johnny Appleseed, appleseeds for gardening/farming, the appleseed in the fruit apple, or appleseed the anime movie?). RawSugar was a wee bit before its time as it is a tool that is needed after there tagging (particularly folksonomy related tagging systems) start scaling. It is a tool that many in enterprise are beginning to seek to help find clarity and greater value in their internal tagging systems they built 12 to 18 months ago or longer. Unfortunately, the venture capitalists did not have the vision that the creators of RawSugar did nor the patience needed for the market to catch-up to the need in a more mature market and they pulled the plug on the development of RawSugar to put the technology to use for another purpose (ironically as the market they needed was just easing into maturity).
The del.icio.us movement drove blog tags, laid out by Technorati. This mirrored the previous methods of publisher tagging, which is most often better served from set categories that usually are derived from a taxonomy or simple set (small or large) of controlled vocabulary terms. Part of the problem inherent in publisher tags and categories is that they are difficult to use outside of their own domain (however wide their domain is intended - a specific site or cross-sites of a publisher). Using tags from one blog to another blog has problems for the same reason that Bitzi and all other publisher tags have and had problems, they are missing identity of the tagger AND a clear common object being tagged. Publisher tags can work well as categories for aggregating similar content within a site or set of commonly published sites where a tag definition has been set (but that really makes them set categories) and used consistently. Using Technorati tag search most often surfaces this problem quickly with many variation of tag use surfacing or tag terms being used to attract traffic for non-related content (Technorati's keyword search is less problematic as it relies on the terms being used in context in the content - unfortunately the two searches have been tied together making search really messy at the moment). There is need for an improved tool that could take the blog tags and marry them to the linked items in the content (if that is what is being talked about - discerning predicate in blog tags is not clear yet).
Current Tools that Advanced
As of a year ago there were more than 140 social bookmarking tools in the consumer space, but there was little advancement. But, there are a few services that have innovated and brought new and valuable features to market in tagging. As mentioned recently Ma.gnolia has done a really good job of taking the next steps with social interaction in social bookmarking. Clipmarks pioneered the sub-page tagging and annotation in the consumer tagging space and has a really valuable resource in that tool. ConnectBeam is doing some really good things in the enterprise space, mostly taking the next couple steps that Yahoo MyWeb2 should have taken and pairing it with enterprise search. Sadly, del.icio.us (according to comments in their discussion board) is under a slow rebuilding of the underlying framework (but many complaints from enterprise companies I have worked with and spoken indepth with complain del.icio.us continually blocks their access and they prefer not to use the service and are finding current solutions and options to be better for them).
A Long Way to Go
While there are examples that tagging services have moved forward, there is so much more room to advance and improve. As people's own collection of tagged pages and objects have grown the tools are needed to better refind them. This will require time search and time related viewing/scanning of items. The ability to use co-occurance of tag terms (what other tags were used on the object), with useful interfaces to view and scan the possibilities.
Portability and interoperability is extremely important for both the individual person and enterprise to aggregate, migrate, and search across their collections across services and devices (now that devices have tagging and have had for some time, as in Mac OS X Tiger and now Vista). Enterprises should also have the ability to move external tagged items in through their firewall and publish out as needed, mostly on an employee level. There is also desire to have B2B tagging with customers tagging items purchased so the invoicing can be in the customers terminology rather than the seller terminology.
One of the advances in personal tagging portability and interoperability can easily be seen when we tag on one device and move the object to a second device or service (parts of this are not quite available yet). Some people will take a photo on their mobile phone and add quick tags like "sset" and others to a photo of a sunset. They send that photo to a service or move it to their desktop (or laptop) and import the photo and the tag goes along with it. The application sees the "sset" and knows the photo was transfered from that person's mobile device and knows it is their short code for "sunset" and expands the tag to sunset accordingly. The person then adds some color attribute tags to the photo and moves the photo to their photo sharing service of choice with the tags appended.
The current tools and services need tools and functionality to heal some of the messiness. This includes stemming to align versions of the same word (e.g. tag, tags, tagging, bookmark, bookmarking). Tag with disambiguation in mind by offering co-occurrence options (e.g. appleseed and anime or johnny or gardening or apple). String matching to identify facets for time and date, names (from your address book), products, secret tag terms (to have them blocked from sharing), etc. (similar to Stikkit and GMail).
Monitoring Tools
Enterprise is what the next development steps really need to take off (these needs also apply to the power knowledge worker as well). The monitoring tools for tags from others and around objects (URLs) really need to fleshed out and come to market. The tag monitoring tools need to become granular based on identity and co-occurance so to more tightly filter content. The ability to monitor a URL and how it is tagged across various services is a really strong need (there are kludgy and manual means of doing this today) particularly for simple and efficient tools (respecting the tagging service processing and privacy).
Analysis Tools
Enterprise and power knowledge workers also are in need of some solid analysis tools. These tools should be able to identify others in a service that have similar interests and vocabulary, this helps to surface people that should be collaborating. It should also look at shifts in terminology and vocabulary so to identify terms to be added to a taxonomy, but also provide an easy step for adding current emergent terms to related older tagged items. Identify system use patterns.
Just the Tip
We are still at the tip of the usefulness of tagging and the tools really need to make some big leaps. The demands are there in the enterprise marketplace, some in the enterprise are aware of them and many more a getting to there everyday as the find the value real and ability to improve the worklife and workflow for their knowledge workers is great.
The people using the tools, including enterprise need to grasp what is possible beyond that is offered and start asking for it. We are back to where we were in 2003 when del.icio.us arrived on the scene, we need new and improved tools that understand what we need and provide usable tools for those solutions. We are developing tag islands and silos that desperately need interoperability and portability to get real value out of these stranded tag silos around or digital life.
Stitching Conversation Threads Fractured Across Channels
Communicating is simple. Well it is simple at its core of one person talking with another person face-to-face. When we communicate and add technology into the mix (phone, video-chat, text message, etc.) it becomes more difficult. Technology becomes noise in the pure flow of communication.
Now With More Complexity
But, what we have today is even more complex and difficult as we are often holding conversation across many of these technologies. The communication streams (the back and forth communication between two or more people) are now often not contained in on communication channel (channel is the flavor or medium used to communicate, such as AIM, SMS, Twitter, e-mail, mobile phone, etc.).
We are seeing our communications move across channels, which can be good as this is fluid and keeping with our digital presence. More often than not we are seeing our communication streams fracture across channels. This fracturing becomes really apparent when we are trying to reconstruct our communication stream. I am finding this fracturing and attempting to stitch the stream back together becoming more and more common as for those who are moving into and across many applications and devices with their own messaging systems.
The communication streams fracture as we pick-up an idea or need from Twitter, then direct respond in Twitter that moves it to SMS, the SMS text message is responded back to in regular SMS outside of Twitter, a few volleys back and forth in SMS text, then one person leaves a voicemail, it is responded to in an e-mail, there are two responses back and forth in e-mail, an hour later both people are on Skype and chat there, in Skype chat they decide to meet in person.
Why Do We Want to Stitch the Communication Stream Together?
When they meet there is a little confusion over there being no written overview and guide. Both parties are sure they talked about it, but have different understandings of what was agreed upon. Having the communication fractured across channels makes reconstruction of the conversation problematic today. The conversation needs to be stitched back together using time stamps to reconstruct everything [the misunderstanding revolved around recommendations as one person understands that to mean a written document and the other it does not mean that].
Increasingly the reality of our personal and professional lives is this cross channel communication stream. Some want to limit the problem by keeping to just one channel through the process. While this is well intentioned it does not meet reality of today. Increasingly, the informal networking leads to meaningful conversations, but the conversations drifts across channels and mediums. Pushing a natural flow, as it currently stands, does not seem to be the best solution in the long run.
Why Does Conversation Drift Across Channels?
There are a few reasons conversations drift across channels and mediums. One reason is presence as when two people notice proximity on a channel they will use that channel to communicate. When a person is seen as present, by availability or recently posting a message in the service, it can be a prompt to communicate. Many times when the conversation starts in a presence channel it will move to another channel or medium. This shift can be driven by personal preference or putting the conversation in a medium or channel that is more conducive for the conversation style between people involved. Some people have a preferred medium for all their conversations, such as text messaging (SMS), e-mail, voice on phone, video chat, IM, etc.. While other people have a preferred medium for certain types of conversation, like quick and short questions on SMS, long single responses in e-mail, and extended conversations in IM. Some people prefer to keep their short messages in the channel where they begin, such as conversations that start in Facebook may stay there. While other people do not pay attention to message or conversation length and prefer conversations in one channel over others.
Solving the Fractured Communication Across Channels
Since there are more than a few reasons for the fractured communications to occur it is something that needs resolution. One solution is making all conversations open and use public APIs for the tools to pull the conversations together. This may be the quickest means to get to capturing and stitching the conversation thread back together today. While viable there are many conversations in our lives that we do not want public for one reason or many.
Another solution is to try to keep your conversations in channels that we can capture for our own use (optimally this should be easily sharable with the person we had the conversation with, while still remaining private). This may be where we should be heading in the near future. Tools like Twitter have become a bridge between web and SMS, which allows us to capture SMS conversations in an interface that can be easily pointed to and stitched back together with other parts of a conversation. E-mail is relatively easy to thread, if done in a web interface and/or with some tagging to pull pieces in from across different e-mail addresses. Skype chat also allows for SMS interactions and allows for them to be captured, searched, and pulled back together. IM conversations can easily be saved out and often each item is time stamped for easy stitching. VoIP conversations are often easily recorded (we are asking permission first, right?) and can be transcribed by hand accurately or be transcribed relatively accurately via speech-to-text tools. Voice-mail can now be captured and threaded using speech-to-text services or even is pushed as an attachment into e-mail in services as (and similar to) JConnect.
Who Will Make This Effortless?
There are three types of service that are or should be building this stitching together the fractured communications across channels into one threaded stream. I see tools that are already stitching out public (or partially public) lifestreams into one flow as one player in this pre-emergent market (Facebook, Jaiku, etc.). The other public player would be telecoms (or network provider) companies providing this as a service as they currently are providing some of these services, but as their markets get lost to VoIP, e-mail, on-line community messaging, Second Life, etc., they need to provide a service that keeps them viable (regulation is not a viable solution in the long run). Lastly, for those that do not trust or want their conversation streams in others hands the personally controlled application will become a solutions, it seems that Skype could be on its way to providing this.
Is There Demand Yet?
I am regularly fielding questions along these lines from enterprise as they are trying to deal with these issues for employees who have lost or can not put their hands on vital customer conversations or essential bits of information that can make the difference in delivering what their customers expect from them. Many have been using Cisco networking solutions that have some of these capabilities, but still not providing a catch all. I am getting queries from various telecom companies as they see reflections of where they would like to be providing tools in a Come to Me Web or facilitating bits of the Personal InfoCloud. I am getting requests from many professionals that want this type of solution for their lives. I am also getting queries from many who are considering building these tools, or pieces of them.
Some of us need these solutions now. Nearly all of us will need these solutions in the very near future.
Folksonomy Provides 70 Percent More Terms Than Taxonomy
While at the WWW Conference in Banff for the Tagging and Metadata for Social Information Organization Workshop and was chatting with Jennifer Trant about folksonomies validating and identifying gaps in taxonomy. She pointed out that at least 70% of the tags terms people submitted in Steve Museum were not in the taxonomy after cleaning-up the contributions for misspellings and errant terms. The formal paper indicates (linked to in her blog post on the research more steve ... tagger prototype preliminary analysis) the percentage may even be higher, but 70% is a comfortable and conservative number.
Is 70% New Terms from Folksonomy Tagging Normal?
In my discussion with enterprise organizations and other clients that are looking to evaluate their existing tagging services, have been finding 30 percent to nearly 70 percent of the terms used in tagging are not in their taxonomy. One chat with a firm who had just completed updating their taxonomy (second round) for their intranet found the social bookmarking tool on their intranet turned up nearly 45 percent new or unaccounted for terms. This firm knew they were not capturing all possibilities with their taxonomy update, but did not realize their was that large of a gap. In building their taxonomy they had harvested the search terms and had used tools that analyzed all the content on their intranet and offered the terms up. What they found in the folksonomy were common synonyms that were not used in search nor were in their content. They found vernacular, terms that were not official for their organization (sometimes competitors trademarked brand names), emergent terms, and some misunderstandings of what documents were.
In other informal talks these stories are not uncommon. It is not that the taxonomies are poorly done, but vast resources are needed to capture all the variants in traditional ways. A line needs to be drawn somewhere.
Comfort in Not Finding Information
The difference in the taxonomy or other formal categorization structure and what people actually call things (as expressed in bookmarking the item to make it easy to refind the item) is normally above 30 percent. But, what organization is comfortable with that level of inefficiency at the low end? What about 70 percent of an organization s information, documents, and media not being easily found by how people think of it?
I have yet to find any organization, be it enterprise or non-profit that is comfortable with that type of inefficiency on their intranet or internet. The good part is the cost is relatively low for capturing what people actually call things by using a social bookmarking tool or other folksonomy related tool. The analysis and making use of what is found in a folksonomy is the same cost of as building a taxonomy, but a large part of the resource intensive work is done in the folksonomy through data capture. The skills needed to build understanding from a folksonomy will lean a little more on the analytical and quantitative skills side than the traditional taxonomy development. This is due to the volume of information supplied can be orders of magnitude higher than the volume of research using traditional methods.
Cuban Clocks and Music Long Tail Discovery
The last two trips to San Francisco I have heard a latin version of Coldplay's Clocks on KFOG and it really intrigued me. This last trip I was in the car for four songs and one of them was Coldplay's Clocks by the Cuban All Stars. I have been trying to track this track down since first hearing, but am not having great luck. This continually happens when I listen to KFOG, which is about the only regular radio station I will listen to (I much prefer XM Radio for is lack of advertising and blathering idiots spouting off while playing overplayed songs that have little merit.
What I like about this version of Clocks by the Cuban All Stars (I have seen the dashboard metadata list it as Ibrahim Ferrer, but it has not been described as such by the DJs on KFOG). This is where my music recommendations break. But, some digging on the KFOG website points me to Rhythms Del Mundo as the source (but their Flash site seems horribly broken in all browsers as none of the links work). I have found the album on iTunes, but only a partial listing and none of the physical music store options have this in stock as it is not mainstream enough (how I miss Tower).
This all seems like far more work that should be needed. But, not if one has even slightly long tail musical interests. I had a wonderful discussion along these lines wish Cory from IODA about this and the lack of really good long tail discovery systems.
I use Last.fm to discover new things from friend#039;s lists, but the Last.fm neighbor recommendations seem to only work on more mainstream interests (Pandora really falls off on the long tail for me). Now if KFOG put their play list in KFOG, it would help greatly and I would add them to my friend list (or I could move back home to the San Francisco Bay Area).
Technosocial Architect
Those of you that know me well know I am not a fan of being labeled, yes it is rather ironic. A large part of this is a breadth of focus in the lens, from which I view the world. I am deeply interested in how people interact, how people use technology, and the role of information in this equation. My main interest is information and information use, when to people want it and need it, how people acquire it. I am utter fascinated by how technology plays in this mix and how important design is. I look at technology as any mediated form of communication, other than face-to-face communication. The quest began in the technology "quot;paper age" looking at layout and design of text and images on the printed page and the actual and latent messages that were portrayed in this medium. I also dove into television and video as well as computer aided visualizations of data (Tufte was required reading in quantitative methods class (stats) in the early '90s in grad school).
Well, this life long interest only continued when I started digging into the web and online services in the early 90s. But, as my interest turned professional from hobby and grad student my training in quantitative and qualitative (ethnographic) research were used not for public policy, but for understanding what people wanted to do with technology or wished it would work, but more importantly how people wanted to use information in their life.
Basis for Digital Design and Development
As I have waded through web development and design (and its various labels). Most everything I have done is still based on the undergrad training in communication theory and organizational communication. Understanding semantics, rhetoric, layout, design, cogsci, media studies, cultural anthropology, etc. all pay a very important part in how I approach everything. It is a multi-disciplinary approach. In the mid-80s I had figured everybody would be using computers and very adept by the time I finished undergrad, that I thought it was a waste to study computer science as it was going to be like typing and it programming was going to be just like typing, in that everybody was going to be doing (um, a wee bit off on that, but what did I know I was just 18).
People Using Information in Their Life
The one thing that was of deep interest then as it is now, is how people use information in their life and want and need to use information in their life. To many people technology gets in the way of their desired ease of use of information. Those of us who design and build in the digital space spend much of our time looking at how to make our sites and applications easier for people to use.
Do you see the gap?
The gap is huge!
We (as designers and developers) focus on making our technology easy to use and providing a good experience in the domain we control.
People want to use the information when they need it, which is quite often outside the domains we as designers and developers control.
Designing for Information Use and Reuse
Part of what I have been doing in the past few years is looking at the interaction between people and information. With technology we have focussed on findability. Great and good. But, we are failing users on what they do with that information and what they want to do with that information. One question I continually ask people (particularly ones I do not know) is how are you going to use that information. When they are reading or scanning information (paper or digital it does not matter) I ask what is important to them in what is before them. Most often they point to a few things on the page that have different uses (an article referenced in the text, an advertisement for a sale, a quote they really like, etc.). But, the thing that nearly everything that they find important is it has a use beyond what they are reading. They want to read the article that is referenced, they want the date and location for the sale (online address or physical address and date and times), they want to put the quote in a presentation or paper they are writing.
End-to-end is Not the Solution
Many companies try to focus on the end-to-end solution. Think Microsoft or Google and their aim to solve the finding, retaining, using, and reusing of that information all within their products. Currently, the companies are working toward the web as the common interface, but regular people do not live their life on the web, they live it in the physical world. They may have a need for an end-to-end solution, but those have yet to become fully usable. People want to use the tools and technologies that work best for them in various contexts. As designers and developers we can not control that use, but we can make our information more usable and reusable. We have to think of the information as the focal point. We have to think of people actually connecting with other people (that is individuals not crowds) and start to value that person to person interaction and sharing on a massive scale.
Our information and its wrappers must be agnostic, but structured and prepared in a manner that is usable in the forms and applications that people actually use. The information (content to some) is the queen and the people are the king and the marriage of the two of them will continue the reign of informed people. This puts technology and the medium as the serf and workers in that kingdom. Technology and the medium is only the platform for information use and reuse of the information that is in people's lives. That platform, like the foundation of a house or any building must not be noticed and must serve its purpose. It must be simple to get the information and reuse it.
Technology and Design are Secondary
Those of us that live and breathe design and development have to realize what we build is only secondary to what people want. It is the information that is important to regular people. We are only building the system and medium. We are the car and the road that take people to Yosemite where they take pictures, build memories, bond with their travel companions, etc. What is created from this trip to Yosemite will last much longer than the car or road they used to get them to the destination. We only build the conduit. We have to understand that relationship. What we build is transient and will be gone, but what people find and discover in the information they find in what we build must last and live beyond what we control and can build or design. We must focus on what people find and want to use and reuse while they are using what we are designing and building for them.
Information as Building Blocks
All of what is being described is people finding and using information that an other person created and use it in their life. This is communication. It is a social activity. This focus is on building social interactions where information is gathered and used in other contexts. Information use and reuse is part of the human social interaction. This social component with two people or more interacting to communicate must be the focus. We must focus on how that interaction shapes other human interactions or reuses of that information garnered in the communication with an other and ease that interaction. If you are still reading (hello) you probably have something to do with design or development of technology that mediates this communication. We are building social tools in which what is communicated will most likely have a desired use for the people interacting outside of what we have built or designed.
Technosocial Architects
People who understand the social interactions between people and the technologies they use to mediate the interactions need to understand the focus is on the social interactions between people and the relationship that technology plays. It is in a sense being a technosocial architect. I ran across the word technosocial in the writings of Mimi Ito, Howard Rheingold, and Bruce Sterling. It always resonates when I hear technosocial. Social beings communicate and inherent in the term communication is information.
Focus on People, Medium, and Use
Just above you see that I referenced three people (Mimi, Howard, and Bruce) as people who used a term that seems to express how I believe I look at the work I do. It is people, more importantly, it is individuals that I can point to that I trust and listen to and are my social interpreters of the world around me. These people are filters for understanding one facet of the world around me. People have many facets to their life and they have various people (sometimes a collective of people, as in a magazine or newspaper) who are their filters for that facet of their life. There are people we listen to for food recommendations, most likely are different from those that provide entertainment, technology, clothing, auto, child care, house maintenance, finance, etc. We have distinct people we learn to trust over time to provide or reinforce the information we have found or created out of use and reuse of what we have interacted with in our life.
Looking at many of the tools available today there is a focus on the crowd in most social tools on the web. Many regular people I talk to do not find value in that crowd. They want to be able to find individual voices easily that they can learn to trust. Just like I have three people I can point to people in social software environments look at the identity (screen name many times) as their touch point. I really like Ask MetaFilter as a social group "question and answer" tool. Why? Mostly because there are screen names that I have grown to know and trust from years of reading MetaFilter. The medium is an environment that exposes identity (identity is cloaked with a screen name and can be exposed if the person so decides in their profile). People are important to people. In digitally mediated social environments the identity is that point of reference that is a surrogate for name in physical space. In print the name of the writer is important as a means to find or avoid other pieces or works. We do the same in movies, television news, television shows, online videos, podcasts, blogs, etc. the list does not end.
Our social mediums need to keep this identity and surface the identity to build trust. People use identity as gatekeepers in a world of information overload. When I look at Yahoo! Answers and Yahoo! MyWeb (my absolute favorite social bookmarking tool) I get dumped into the ocean of identities that I do not recognize. People are looking for familiarity, particularly familiarity of people (or their surrogate identity). In MyWeb I have a community (unfortunately not one that is faceted) where I trust identities (through a series of past experience) as filters for information in the digital world around us, but I am not placed in this friendly environment, but put in an environment where I find almost nothing I value presented to me. This is the way Yahoo! Answers works as well, but it does not seem like there is the ability to track people who ask or answer questions that a person would find value in.
The tools we use (as well as design and build) must understand the value of person and identity as information filters. The use of information in our lives is one explicit expression of our interest in that subject, the person who created the information, or the source what housed that information. Use and reuse of information is something we need to be able to track to better serve people (this gets in to the area of digital rights management, which usually harms information use more than it enables it, but that is another long essay). The medium needs to understand people and their social interaction people have with the information and the people who create the information and the desired use. This use goes well beyond what we create and develop. Use requires us understanding we need to let go of control of the information so it may be used as people need.
Need for Technosocial Architects
Looking at the digital tools we have around us: websites, social computing services and tools (social networking sites, wikis, blogs, mobile interaction, etc.), portals, intranets, mobile information access, search, recommendation services, personals, shopping, commerce, etc. and each of these is a social communication tool that is based on technology. Each of these has uses for the information beyond the digital walls of their service. Each of these has people who are interacting with other people through digital technology mediation. This goes beyond information architecture, user experience design, interaction design, application development, engineering, etc. It has needs that are more holistic (man I have been trying to avoid that word) and broad as well as deep. It is a need for understanding what is central to human social interactions. It is a need for understanding the technical and digital impact our tools and services have in mediating the social interaction between people. It is a need for understanding how to tie all of this together to best serve people and their need for information that matters to them when they want it and need it.
Cultures of Simplicity and Information Structures
Two Conferences Draw Focus
I am now getting back to responding to e-mail sent in the last two or three weeks and digging through my to do list. As time wears I am still rather impressed with both XTech and the Microlearning conferences. Both have a focus on information and data that mirrors my approaches from years ago and are the foundation for how I view all information and services. Both rely on well structured data. This is why I pay attention and keep involved in the information architecture community. Well structured data is the foundation of what falls into the description of web 2.0. All of our tools for open data reuse demands that the underlying data is structured well.Simplicity of the Complex
One theme that continually bubbled up at Microlearning was simplicity. Peter A. Bruck in his opening remarks at Microlearning focussed on simplicity being the means to take the complex and make it understandable. There are many things in the world that are complex and seemingly difficult to understand, but many of the complex systems are made up of simple steps and simple to understand concepts that are strung together to build complex systems and complex ideas. Every time I think of breaking down the complex into the simple components I think of Instructables, which allows people to build step-by-step instructions for anything, but they make each of the steps as reusable objects for other instructions. The Instructables approach is utterly brilliant and dead in-line with the microlearning approach to breaking down learning components into simple lessons that can be used and reused across devices, based on the person wanting or needing the instruction and providing it in the delivery media that matches their context (mobile, desktop, laptop, tv, etc.).
Simple Clear Structures
This structuring of information ties back into the frameworks for syndication of content and well structured data and information. People have various uses and reuses for information, data, and media in their lives. This is the focus on the Personal InfoCloud. This is the foundation for information architecture, addressable information that can be easily found. But, in our world of information floods and information pollution due to there being too much information to sort through, findability of information is important as refindability (this is rarely addressed). But, along with refindability is the means to aggregate the information in interfaces that make sense of the information, data, and media so to provide clarity and simplicity of understanding.
Europe Thing Again
Another perspective of the two conferences was they were both in Europe. This is not a trivial variable. At XTech there were a few other Americans, but at Microlearning I was the only one from the United States and there were a couple Canadians. This European approach to understanding and building is slightly different from the approach in the USA. In the USA there is a lot of building and then learning and understanding, where as in Europe there seems to be much more effort in understanding and then building. The results are somewhat different and the professional nature of European products out of the gate where things work is different than in the USA. This was really apparent with System One, which is an incredible product. System One has all the web 2.0 buzzwords under the hood, but they focus on a simple to use tool that pulls together the best of the new components, but only where it makes sense to create a simple tool that addresses complex problems.
Culture of Understanding Complex to Make Simple
It seems the European approach is to understand and embrace the complex and make it simple through deep understanding of how things are built. It is very similar to Instructables as a culture. The approach in the USA seems to include the tools, but have lacked the understanding of the underlying components and in turn have left out elements that really embrace simplicity. Google is a perfect example of this approach. They talk simplicity, but nearly every tool is missing elements that make it fully usable (calendar not having sync, not being able to only have one or two Google tools on rather than everything on). This simplicity is well understood by the designers and they have wonderful solutions to the problems, but the corporate culture of churning things out gets in the way.
Breaking It Down for Use and Reuse
Information in simple forms that can be aggregated and viewed as people need in their lives is essential to us moving forward and taking the pain out of technology that most regular people experience on a daily basis. It is our jobs to understand the underlying complexity, create simple usable and reusable structures for that data and information, and allow simple solutions that are robust to be built around that simplicity.
To the Skies Again
I am off again, but this time I have clothes out of the cleaners and laundry done. The turn around from last trip to this trip was only a couple days. I am looking forward to being home for a bit, after this trip. I have about 18 hours of travel before I get where I am going.
I am quite looking forward to being with many people that are passionate about microcontent and microlearning. A conversation in early 2001 got me completely hooked on microcontent and its possibilities. We are finally beginning to see tangents of the microcontent world slip into use in the world of the general public. APIs, aggregation, tracking, metadata access, pushing to mobile, etc. are all components, when they work right. We are only a slice of the way there, but each little step gets better and better.
The Battle to Build the Personal InfoCloud
Over at Personal InfoCloud I posted The Future is Now for Information Access, which was triggered by an interview with Steve Ballmer (Microsoft) about the future of technology and information. I do not see his future 10 years out, but today. I see the technology in the pockets of people today. People are frustrated with the information not being easily accessed and use and reuse not being as simple as it should. Much of this is happening because of the structure of the information.
Personal InfoCloud is the Focus
One thing that struck me from the article, which I did not write about, was the focus on Google. Personally I find it odd as Yahoo is sitting on the content and the structure for more than 90 percent of what is needed to pull off the Personal InfoCloud. Yahoo is beginning to execute and open access to their data in proper structures. Ballmer lays out a nearly exact scenario for aggregating one's own information and putting it in our lives to the one I have been presenting the last few years. Yahoo has the components in place today to build on top of and make it happen. Google is not only lacking the structure, but they are not executing well on their products they produce. Google does the technically cool beta, but does not iterate and fix the beta nor are they connecting the dots. Yahoo on the other hand is iterating and connecting (they need to focus on this with more interest, passion, and coordinated direction).
The Real Battle
I really do not see the battle as being between Google and the others. The real battle is between Yahoo and Microsoft. Why? Both focus on the person and that person's use and need for information in their life and with their context. Information needs to be aggregated (My Yahoo is a great start, but it goes deeper and broader) and filtered based on interest and need. We are living in a flood of information that has crossed into information pollution territory. We need to remove the wretched stench of information to get back the sweet smell of information. We need to pull together our own creations across all of the places we create content. We need to attract information from others whom have similar interests, frameworks, and values (intellectual, social, political, technological, etc.). The only foundation piece Yahoo is missing is deep storage for each person's own information, files, and media.
Microsoft Live Gets It
Microsoft has the same focus on the person. I have become intrigued with the Microsoft Live properties (although still have a large disconnect with their operating systems and much of their software). Live is aiming where Yahoo is sitting and beyond. Microsoft has the cash and the interest to assemble the pieces and people to get there. Live could get there quickly. Looking at the Live products I saw in January at Search Champs with some in relatively early states and what was launched a few months later, the are iterating quickly and solidly based on what real people want and need in their lives (not the alpha geeks, which Google seems to target). Live products are not done and the teams are intact and the features and connections between the components are growing. They are leaving Google in the dust.
Can Yahoo Stay Ahead of Microsoft?
The question for Yahoo is can they keep up and keep ahead of Microsoft? Google has the focus in search as of today (not for me as the combination of Yahoo! MyWeb 2.0 and Yahoo! Search combined blow away anything that Google has done or seemingly can do. Yahoo! does need to greatly improve the simplicity, ease of use, and payoff (it takes a while for the insanely great value of MyWeb 2.0 to kick in and that needs to come much earlier in the use phase for regular people).
I am seeing Microsoft assembling teams of smart passionate people who want to build a killer web for regular people. It seems Ray Ozzie was the turn around for this and is part of the draw for many heading to work on Live products. The competition for minds of people who get it puts Live in competition with Google, Yahoo, EBay, Amazon, and even Apple. I am seeing Live getting the people in that they need. Recently (last week) Microsoft even started changing their benefits and employee review practices to better compete and keep people. It seems that they are quite serious and want to make it happen now.
Yahoo Under Valued
Recent comments about Yahoo being under valued in the long term are dead on in my view. A recent Economist article about Google pointed out how poorly they execute on everything but their core service (search). This waking up starts to bring a proper focus on what those of us who look at regular people and their needs from information and media in their lives have been seeing, Yahoo gets it and is sitting on a gold mine. Yahoo has to realize that Microsoft sees the same thing and is pushing hard with a proper focus and passion to get there as well.
Google Overvalued
What does this mean for Google? I am not sure. Google is a technology company that is focussed on some hard problems, but it has to focus on solutions that people can use. Google aims for simple interfaces, but does not provide simple solutions or leaves out part of the solutions to keep it simple. They need a person-centered approach to their products. The addition of Jeff Veen and his Measure Map team should help, if they listen. Google has some excellent designers who are focussed on usable design for the people, but it seems that the technology is still king. That needs to change for Google to stay in the game.
Live Data Could Solve the Social Bookmarking Problem with Information Volatility
Alex brings up something in his Go and microformat stuff! covering what is in the works with Microformats at Microsoft. Scroll down to where Alex talks about "mRc = Live data wiring", now this live data access is incredibly important.
One of the elements that has been bugging me with social bookmarking it the volatility of the information is not taken into account when the bookmark is made. No, I am not talking about the information blowing up, but the blood pressure of the person bookmarking may rise if the data changes in some way. I look at social bookmarking, or bookmarking in general as a means to mark a place, but it fails as an indicator of state or status change of the information we are pointing to. The expressing of bookmarking and/or tagging is an expression of our explicit interest in that object we bookmarked and/or tagged. The problem is our systems so far are saying, "yes, you have interest, but so what".
What the live data approach does is makes our Personal InfoCloud active. If we could bookmark information and/or tag chunks of information as important we should be able to find out when that information changes, or better get an alert before the information changes. One area where this is essential and will add huge value is shopping. What happens with products in the real world? The prices change, they go out of stock, the product is modified, production of the product stopped, etc. The permeations are many, but those expressing interest should be alerted and have their information updated.
One of the things I have been including in my "Come to Me Web" presentations is the ability to think about what a person needs when they use and want to reuse information. We read about a product we desire, we read the price, but we may think about the product or put it on a wish list that is related to an event in the future. When we go to act on the purchase the information we have gathered and bookmarked may be out of date.
One solution I have been talking about in my presentations is providing an RSS/ATOM feed for the page as it is bookmarked so the person gets the ability to get updated information. I have built similar functionality into past products years ago that let people using data know when the data changed (e-mail) but also provided the means to show what the data was prior and what it had changed to. It was functionality that was deeply helpful to the users of the system. Live data seems a more elegant solution, if it provides the means to see what information had changed should the person relying on or desiring the information want it.
Structured Blogging has (Re)Launched
Structured Blogging has launched and it may be one of the brightest ideas of 2005. This has the capability to pull web services into nearly every page and to aggregate information more seamlessly across the web. The semantic components help pull all of this together so services can be built around them.
This fits wonderfully in the Model of Attraction framework by allowing people and tools to attract the information they want, in this case from all around the web far more easily than ever before.
[Update] A heads-up from Ryan pointed out this is a relaunch. Indeed, Structured Blogging is pointing out all of the groups that are supporting and integrating the effort. The newest version is of Structured Blogging is now microformat friendly (insanely important).
Folksonomy Definition and Wikipedia
Today, having seen an new academic endeavor related to folksonomy quoting the Wikipedia entry on folksonomy and I realize the definition of Folksonomy has become completely unglued from anything I recognize (yes, I did create the word to define something that was undefined prior). It is not collaborative, it is not putting things in to categories, it is not related to taxonomy (more like the antithesis of a taxonomy), etc. The Wikipedia definition seems to have morphed into something that the people with Web 2.0 tagging tools can claim as something that can describe their tool (everybody wanted to be in the cool crowd). I hope folksonomy still has value as a word to point something different in the world of tagging than the mess that went before it. It is difficult to lose the pointer to something distinct makes understanding what works well. Using folksonomy and defining it to include the mess that was all of tagging and is still prevalent in many new tools dilutes the value.
Folksonomy Is
Folksonomy is the result of personal free tagging of information and objects (anything with a URL) for one's own retrival. The tagging is done in a social environment (shared and open to others). The act of tagging is done by the person consuming the information.
The value in this external tagging is derived from people using their own vocabulary and adding explicit meaning, which may come from inferred understanding of the information/object as well as. The people are not so much categorizing as providing a means to connect items and to provide their meaning in their own understanding.
Deriving Value from Folksonomy
There tremendous value that can be derived from this personal tagging when viewing it as a collective when you have the three needed data points in a folksonomy tool: 1) the person tagging; 2) the object being tagged as its own entity; and 3) the tag being used on that object. Flattening the three layers in a tool in any way makes that tool far less valuable for finding information. But keeping the three data elements you can use two of the elements to find a third element, which has value. If you know the object (in del.icio.us it is the web page being tagged) and the tag you can find other individuals who use the same tag on that object, which may lead (if a little more investigation) to somebody who has the same interest and vocabulary as you do. That person can become a filter for items on which they use that tag. You then know an individual and a tag combination to follow. The key is knowing who and what specifically is being tagged.
Social Tagging
There are other tagging efforts that are done for socially connecting others and others where people are tagging their own information for others. I have been to workshops where items on the web were tagged with a term that was agreed upon for tagging these objects across tools. This allows the person to retrieve information/objects connected with that event as well as others getting access to that information/object. Does it fall into the definition of folksonomy? This gets fuzzy. It is for the retrieval of the person tagging the information, so it could fit. It gets close to people tagging information solely for others, which does not get to a folksonomy, it is what Cory Doctorow labeled Metacrap.
Academics Quoting Wikipedia
Sadly, I have had 15 to 20 academic papers sent to me or links to them sent to me in the past year. No two of them use the same definition. Everyone of them points to Wikipedia. Not one of the papers points to the version of the page.
The lack of understanding the medium of a Wiki, which is very fluid, but not forgetful, is astonishing. They have been around for three or four years, if not longer. It is usually one of the first lessons anybody I have known learns when dealing with a Wiki, they move and when quoting them one must get the version of the information. They are a jumping off point, not destinations. They are true conversations, which have very real etherial qualities.
Is there no sence of research quality? Quoting a Wiki entry without pointing to the revision is like pointing to Time magazine without a date or issue number. Why is there no remedial instruction for using information in a Wiki?
Personal Love of Wikis
Personally, I love Wikis and they are incredible tools, but one has to understand the boundaries. Wikis are emergent information tools and they are social tools. They are one of the best collaboration tools around, they even work very well for personal uses. But, like anything else it takes understanding on how to use them and use the information in them.
Del.icio.us and MyWeb Combo Bookmarklet
I took two of my favorite bookmarklets (for del.icio.us and Yahoo MyWeb 2, put them in my javascript collider to get a Combo Tag Tool (drag this to your browser's bookmark bar.
By clicking on this bookmarklet you get the del.icio.us tag interface populated with the title. You also get a MyWeb entry pop-up window.
I have been seeing the early benefits of Yahoo's MyWeb, but I also want to keep the community I have in del.icio.us. Keeping both up to date and in sync is my goal and hopefully this will help you do the same.
Tagging Article at OK/Cancel
OK/Cancel posted a quick article on tagging I pulled wrote (mostly pulled out of e-mail responses). The article is Tagging for Fun and Finding, which includes mention of folksonomy.
Explaining and Showing Broad and Narrow Folksonomies
I have been explaining the broad and narrow folksonomy in e-mail and in comments on others sites, as well as in the media (Wired News). There has still been some confusion, which is very understandable as it is a different concept that goes beyond a simple understanding of tagging. I have put together a couple graphics that should help provide a means to make this distinction some what clearer. The folksonomy is a means for people to tag objects (web pages, photos, videos, podcasts, etc., essentially anything that is internet addressable) using their own vocabulary so that it is easy for them to refind that information again. The folksonomy is most often also social so that others that use the same vocabulary will be able to find the object as well. It is important to note that folksonomies work best when the tags used to describe objects are in the common vocabulary and not what a person perceives others will call it (the tool works like no other for personal information management of information on the web, but is also shared with the world to help others find the information).
Broad Folksonomy
Let's begin with the broad folksonomy, as a tool like del.icio.us delivers. The broad folksonomy has many people tagging the same object and every person can tag the object with their own tags in their own vocabulary. This lends itself very easy to applying the power law curve (power curve) and/or net effect to the results of many people tagging. The power terms and the long tail both work.
The broad folksonomy is illustrated as follows. 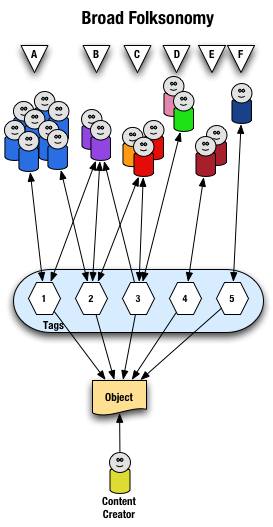
From a high level we see a person creates the object (content) and makes it accessible to others. Other people (groups of people with the same vocabulary represented people blobs and noted with alphabet letters) tag the object (lines with arrows pointing away from the people) with their own terms (represented by numbers). The people also find the information (arrows on lines pointing from the numeric tags back to the people blobs) based on the tags.
Digging a little deeper we see quite a few people (8 people) in group "A" and they have tagged the object with a "1" and a "2" and they use this term to find the object again. Group "B" (2 people) have applied tag "1" and "2" to the object and they use tag terms "1", "2", and "3" to find the information. Group "C" (3 people) have tagged the object with "2" and "3" so that they can find the object. Group "D" has also tagged the object with tag "3" so that they may refind the information this group may have benefitted from the tagging that group "C" provided to help them find the information in the first place. Group "E" (2 people) uses a different term, "4", to tag the object than others before it and uses only this term to find the object. Lastly, group "F" (1 person) uses tag "5" on the object so that they may find it.
Broad Folksonomy and the Power Curve
The broad folksonomy provides a means to see trends in how a broad range are tagging one object. This is an opportunity to see the power law curve at work and show the long-tail.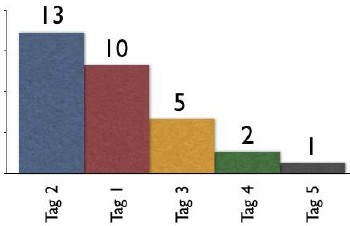
The tags spike with tag "2" getting the largest portion of the tags with 13 entries and tag "1" receiving 10 identical tags. From this point the trends for popular tags are easy to see with the spikes on the left that there are some trends, based on only those that have tagged this object, that could be used extract a controlled vocabulary or at least know what to call the object to have a broad spectrum of people (similar to those that tagged the object, and keep in mind those that tag may not be representative of the whole). We also see those tags out at the right end of the curve, known as the long tail. This is where there is a small minority of people who call the object by a term, but those people tagging this object would allow others with a similar vocabulary mindset to find the object, even if they do not use the terms used by the masses over at the left end of the curve. If we take this example and spread it out over 400 or 1,000 people tagging the same object we will se a similar distribution with even more pronounced spikes and drop-off and a longer tail.
This long tail and power curve are benefits of the broad folksonomy. As we will see the narrow folksonomy does not have the same properties, but it will have benefits. These benefits are non-existent for those just simply tagging items, most often done by the content creator for their own content, as is the means Technorati has done, even with their following tag links to destinations other than Technorati (as they initially had laid out). The benefits of the long tail and power curve come from the richness provided by many people openly tagging the same object.
Narrow Folksonomy
The narrow folksonomy, which a tool like Flickr represents, provides benefit in tagging objects that are not easily searchable or have no other means of using text to describe or find the object. The narrow folksonomy is done by one or a few people providing tags that the person uses to get back to that information. The tags, unlike in the broad folksonomy, are singular in nature (only one tag with the term is used as compared to 13 people in the broad folksonomy using the same tag). Often in the narrow folksonomy the person creating the object is providing one or more of the tags to get things started. The goals and uses of the narrow folksonomy are different than the broad, but still very helpful as more than one person can describe the one object. In the narrow the tags are directly associated with the object. Also with the narrow there is little way of really knowing how the tags are consumed or what portion of the people using the object would call it what, therefore it is not quite as helpful as finding emerging vocabulary or emergent descriptions. We do find that tags used to describe are also used for grouping, which is particularly visible and relevant in Flickr (this is also done in broad folksonomies, but currently not to the degree of visibility that it is done on Flickr, which may be part of the killer interactive environment Ludicorp has created for Flickr).
The narrow folksonomy is illustrated as follows.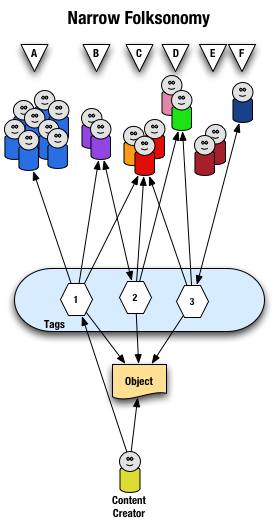
From a high level we see a person creates the object and applies a tag ("1") that represents what they call the object or believe describes the object. There are fewer tags provided than in a broad folksonomy and there is only one of each tag applied to the object. The consumers of the object also can apply tags that help them find the object or describe what they believe are the terms used to describe this object.
A closer look at the interaction between people and the object and tags in a narrow folksonomy shows us that group "A" uses tag "1" to find and come back to the object (did the creator do this on purpose? or did she just tag it with what was helpful to her). We see group "B" also using tag "1" to find the object, but they have tagged the object with tag "2" to also use as a means to find the object. Group "C" uses tag "1","2", and "3" to find the object and we also note this group did not apply any of its own tags to the object as so is only a consumer of the existing folksonomy. We see group "D" uses tags "2" and "3" to find the objects and it too does not add any tags. Group "E" is not able to find the object by using tags as the vocabulary it is using does not match any of the tags currently provided. Lastly, group "F" has their own tag for the object that they alone use to get back to the object. Group "F" did not find the object through existing tags, but may have found the object through other means, like a friend e-mailed them a link or the object was included in a group they subscribe to in their feed aggregator.
We see that the richness of the broad folksonomy is not quite there in a narrow folksonomy, but the folksonomy does add quite a bit of value. The value, as in the case of Flickr, is in text tags being applied to objects that were not findable using search or other text related tools that comprise much of how we find things on the internet today. The narrow folksonomy does provide various audiences the means to add tags in their own vocabulary that will help them and those like them to find the objects at a later time. We are much better off with folksonomies than we were with out them, even if it is a narrow folksonomy being used.
Conclusion
We benefit from folksonomies as the both the personal vocabulary and the social aspects help people to find and retain a tether to objects on the web that are an interest to them. Who is doing the tagging is important to understand and how the tags are consumed is an important factor. This also helps us see that not all tagging is a folksonomy, but is just tagging. Tagging in and of its self is a helpful step up from no tagging, but is no where near as beneficial as opening the tagging to all. Folksonomy tagging can provide connections across cultures and disciplines (an knowledge management consultant can find valuable information from an information architect because one object is tagged by both communities using their own differing terms of practice). Folksonomy tagging also makes up for missing terms in a site's own categorization system/taxonomy. This hopefully has made things a little clearer for all in our understanding the types of folksonomies and tagging and the benefits that can be derived.
This entry first appeared at Personal InfoCloud and comments are open for your use there.
Amazon and A9 Provide Yellow Pages with Photos
Everybody is talking about Amazon's (A9) Yellow Pages today. Amazon has done a decent job bringing photos into their Yellow Pages for city blocks. This is a nice touch, but it is missing some interaction and interconnections between the photos and the addresses, I hope this will come. I really would like to be able to click on a photo and have the Yellow Pages information show up, everything I tried on Clement Street in San Francisco, California did not work that way.
One of the things that really hit me in playing with the tool today at lunch was how the Yellow Pages still suck. I have had problems with the Yellow Pages for..., well ever. I grew up in cross-cultural environments with British and French influences in my day-time care givers growing up. I moved around a fair amount (up and down the West Coast growing up and Europe and the U.S. East Coast). Culture has their own vocabulary (let alone language) for the same items. What I call things, depends on context, but no matter what, the Yellow Pages do not match what I wish to call what I want (or sometimes need).
Today's search I used one of the Amazon search sample, "Optica", which had some nice references. Knowing how I usually approach using the Yellow Pages I search for glasses (as that is what I need to get or need repaired) or contacts. Doing this in a paper Yellow Pages usually returned nothing or pointers to a couple other places. One would thing online Yellow Pages to be different, well they are, they returned nothing related. Glasses returns restaurant supply and automotive window repairs with not one link to eye glasses, nor a reference to "you may be looking for...".
A9 is a great search tool and Amazon.com has great product tools and incredible predictability algorithms, which will be very helpful down the road for the Personal InfoCloud, but the current implementation is still a little rough. I can see where they are heading with this. And I can dream that I would have this available for a mobile device at some point in the next two or three years.
Once very nice piece that was integrated was reviews and ratings of Yellow Pages entries. This is great for the future, once they get filled out. It will also be great once it is available from mobile device (open API so we can start building a useful tool now?). But, it brings my scenario of the future to light rather quickly, where I am standing in front of a restaurant looking at over 100 restaurant reviews on my mobile device. There is no way that I can get through all of these reviews. Our supporting full complement of context tools will be needed to get pulled into play to get me a couple or four good reviews that will mean something to me.
This is but a small slice of the Personal InfoCloud, which is much broader and focusses on enabling the person to leverage the information they have and find. Pairing these two and enabling easy access to that information when it is needed.
Folksonomy Explanations
The past few weeks have seen my inbox flooded with folksonomy questions. I am going to make things easier on my inbox by posting some common discussions here. Many of the items I am posting I have posted else where, but this will also be a great help for me.
There have been many people who have correctly discerned a difference between the two prime folksonomy examples, Flickr and del.icio.us. As I first stated in a comment to Clay Shirky's first article on Folksonomy, there are two derivations of folksonomy. There is a narrow folksonomy and a broad folksonomy. On August 26th I stated...
Clay, you bring in some very good points, particularly with the semantic differences of the terms film, movie, and cinema, which defy normalization. A broad folksonomy, like del.icio.us, allows for many layers of tagging. These many layers develop patterns of consistency (whether they are right or wrong in a professional's view is another matter, but that is what "the people" are calling things). These patterns eventually develop quasi power law for around the folk understanding of the terms as they relate to items.
Combining the power tags of "skateboarding, tricks, movie " (as you point out) will get to the desired information. The hard work of building a hierarchy is not truly essential, but a good tool that provides ease of use to tie the semantic tags is increasingly essential. This is a nascent example of a semantic web. What is really nice is the ability to use not only the power tags, but also the meta-noise (the tags that are not dominant, but add semantic understanding within a community). In the skateboarding example a meta-noise tag could be gnarly that has resonance in the skate community and adds another layer of refinement for them.
The narrow-folksonomy, where one or few users supply the tags for information, such as Flickr, does not supply power tags as easily. One or few people tagging one relatively narrowly distributed item makes normalizing more difficult to employ an tool that aggregates terms. This situation seems to require a tool up front that prompts the individuals creating the tags to add other, possibly, related tags to enhance the findability of the item. This could be a tool that pops up as the user is entering their tags that asks, "I see you entered mac do you want to add fruit, computer, artist, raincoat, macintosh, apple, friend, designer, hamburger, cosmetics, retail, daddy tag(s)?"
This same distinction is brought up on IAWiki' Folksonomy entry.
Since this time Flickr has added the ability for friends and family (and possibly contacts) to add tags, which gives Flickr a broader folksonomy. But, the focus point is still one object that is being tagged, where as del.icio.us has many people tagging one object. The broad-folksonomy is where much of the social benefit can be derived as synonyms and cross-discipline and cross-cultural vocabularies can be discovered. Flickr has an advantage in providing the individual the means to tag objects, which makes it easier for the object to get found.
This brings to the forefront the questions about Google's Gmail, which allows one person the ability to freely tag their e-mail entries. Is Gmail using a folksonomy? Since Gmail was included in the grouping of on-line tools that were in the discussion of what to call these things (along with Flickr and del.icio.us) when folksonomy was coined I say yes. But, my belief that Gmail uses a folksonomy (regular people's categorization through tagging) relates to it using the same means of one person adding tags so that object can be found by them. This is identical to how people tag in Flickr (as proven by the self-referential "me" that is ever prevalent) and del.icio.us. People tag in their own vocabulary for their own retrieval, but they also will tag for social context as well, such as Flickr's "MacWorld" tags. In this case Wikipedia is a little wrong and needs improving.
I suppose Gmail would be a personal folksonomy to the Flickr narrow folksonomy and the del.icio.us broad folksonomy. There are distinct futures for all three folkonomies to grow. Gmail is just the beginning of personal tagging of digital objects (and physical objects tagged with digital information). Lou Rosenfeld hit the nail on the head when he stated, "I'm not certain that the product of folksonomy development will have much long term value on their own, I'll bet dollars to donuts that the process of introducing a broader public to the act of developing and applying metadata will be incredibly invaluable.". These tools, including Gmail, are training for understanding metadata. People will learn new skills if they have a perceived greater value (this is why millions of people learned Palm's Graffiti as they found a benefit in learning the script).
Everybody has immense trouble finding information in their hierarchal folders on their hard drive. Documents and digital objects have more than one meaning than the one folder/directory, in which they reside. Sure there are short cuts, but tracking down and maintaining shortcuts is insanely awkward. Tags will be the step to the next generation of personal information managment.
From Tags to the Future
Merlin hit on something in his I Want a Pony: Snapshots of a Dream Productivity App where he discusses:
Tags - People have strong feelings about metadata and the smart money is usually against letting The User apply his or her own tags and titles for important shared data ("They do it wrong or not at all," the burghers moan). But things are changing for personal users. Two examples? iTunes and del.icio.us. Nobody cares what "metadata" means, but they for damn sure know they want their mp3s tagged correctly. Ditto for del.icio.us, where Master Joshua has shown the world that people will tag stuff thatââ¬â¢s important in their world. Don't like someone else's homebrewed taxonomy? Doesn't matter, because you don't need to like it. If I have a repeatable system for tagging the information on just my Mac and it's working for me, that's really all that matters. I would definitley love that tagging ability for the most atomic piece of any work and personal information I touch.
This crossed my radar the same time as I read Jeff Hawkins' discussion about how he came up with Graffiti for Palm devices. He noticed people did not find touch typing intuitive, but they saw the benefit of it and it worked. Conversely in the early 90s people were interacting with handwriting interpreters that often did not understand one's own handwriting. Jeff came up with something that would give good results with a little bit of effort put in. Palm and Graffiti took off. (Personally, I was lucky when I got my first Palm, in that I was on the west coast and waking on east coast time, which gave me two or three hours of time to learn Graffiti before anybody else was awake. It only took two or three days to have it down perfectly).
Merlin's observation fits within these parameters. Where people have not cared at all about metadata they have learned to understand the value of good tags and often do so in a short period of time. iTunes really drives the value of proper tagging home to many (Napster and other shared music environments brought to light tagging to large segments of the population). In a sense folksonomies of del.icio.us and Flickr are decedents of the shared music environments. People could see that tagged objects, whose tags to be edited and leveraged had value in one's ability to find what one is looking for based on those tags.
As the web grew up on deep linking and open environments to find and share information. So to will tagging become that mantra for the masses. All objects, both digital and physical, will be tagged to provide immediacy of information access so to gain knowledge. Learning to search, parse, filter, and leverage predictive tools (ones that understand the person's desires, context, situation, and frame of reference so to quickly (if not instantly) gather, interpret, and make aware the information around the person). Should the person be late for a meeting their predictive filters are going to limit all be the required information, possibly a traffic jam on their normal route as well as their option A route. A person that has some free time may turn up the serendipity impact and get exposed to information they may normally have filtered out of their attention. The key will be understanding tags have value and just as metadata for other objects, like e-mail subject lines, can be erroneous and indicators of spam, our life filters will need the same or similar. We will want to attract information to us that we desire and will need to make smart and informed choices and tags are just one of the means to this end.
Flickr and the Future of the Internet
Peter's post on Flickr Wondering triggers some thoughts that have been gelling for a while, not only about what is good about Flickr, but what is missing on the internet as we try to move forward to mobile use, building for the Personal InfoCloud (allowing the user to better keep information the like attracted to them and find related information), and embracing Ubicomp. What follows is my response to Peter's posting, which I posted here so I could keep better track of it. E-mail feedback is welcome. Enjoy...
You seemed to have hit on the right blend of ideas to bring together. It is Lane's picture component and it is Nadav's integration of play. Flickr is a wonderfully written interactive tool that adds to photo managing and photo sharing in ways that are very easy and seemingly intuitive. The navigations is wonderful (although there are a few tweak that could put it over the top) and the integration of presentational elements (HTML and Flash) is probably the best on the web as they really seem to be the first to understand how to use which tools for what each does best. This leads to an interface that seems quick and responsive and works wonderfully in the hands of many. It does not function perfectly across platforms, yet, but using the open API it is completely possible that it can and will be done in short order. Imagine pulling your favorites or your own gallery onto your mobile device to show to others or just entertain yourself.
Flickr not only has done this phenomenally well, but may have tipped the scales in a couple of areas that are important for the web to move forward. One area is an easy tool to extract a person's vocabulary for what they call things. The other is a social network that makes sense.
First, the easy tool for people to add metadata in their own vocabulary for objects. One of the hinderances of digital environments is the lack of tools to find objects that do not contain words the people seeking them need to make the connection to that object they are desiring. Photos, movies, and audio files have no or limited inherent properties for text searching nor associated metadata. Flickr provides a tool that does this easily, but more importantly shows the importance of the addition of metadata as part of the benefit of the product, which seems to provide incentive to add metadata. Flickr is not the first to go down this path, but it does it in a manner that is light years ahead of nearly all that came before it. The only tools that have come close is HTML and Hyperlinks pointing to these objects, which is not as easy nor intuitive for normal folks as is Flickr. The web moving forward needs to leverage metadata tools that add text addressable means of finding objects.
Second, is the social network. This is a secondary draw to Flickr for many, but it is one that really seems to keep people coming back. It has a high level of attraction for people. Part of this is Flickr actually has a stated reason for being (web-based photo sharing and photo organizing tool), which few of the other social network tools really have (other than Amazon's shared Wish Lists and Linkedin). Flickr has modern life need solved with the ability to store, manage, access, and selectively share ones digital assets (there are many life needs and very few products aim to provide a solution for these life needs or aims to provide such ease of use). The social network component is extremely valuable. I am not sure that Flickr is the best, nor are they the first, but they have made it an easy added value.
Why is social network important? Helping to reduct the coming stench of information that is resultant of the over abundance of information in our digital flow. Sifting through the voluminous seas of bytes needs tools that provide some sorting using predictive methods. Amazon's ratings and that matching to other's similar patterns as well as those we claim as our friends, family, mentors, etc. will be very important in helping tools predict which information gets our initial attention.
As physical space gets annotated with digital layers we will need some means of quickly sorting through the pile of bytes at the location to get a handful that we can skim through. What better tool than one that leverages our social networks. These networks much get much better than they are currently, possibly using broader categories or tags for our personal relationships as well as means of better ranking extended relationships of others as with some people we consider friends we do not have to go far in their group of friends before we run into those who we really do not want to consider relevant in our life structures.
Flickr is showing itself to be a popular tool that has the right elements in place and the right elements done well (or at least well enough) to begin to show the way through the next steps of the web. Flickr is well designed on many levels and hopefully will not only reap the rewards, but also provide inspiration to guide more web-based tools to start getting things right.
Would We Create Hierarchies in a Computing Age?
Lou has posted my question:
Is hierarchy a means to classify and structure based on the tools available at the time (our minds)? Would we have structured things differently if we had computers from the beginning?
Hierarchy is a relatively easy means of classifying information, but only if people are familiar with the culture and topic of the item. We know there are problems with hierarchy and classification across disciplines and cultures and we know that items have many more attributes that which provide a means of classification. Think classification of animals, is it fish, mammal, reptile, etc.? It is a dolphin. Well what type of dolphin, as there are some that are mammal and some that are fish? Knowing that the dolphin swims in water does not help the matter at all in this case. It all depends on the context and the purpose.
Hierarchy and classification work well in limited domains. In the wild things are more difficult. On the web when we are building a site we often try to set hierarchies based on the intended or expected users of the information. But the web is open to anybody and outside the site anybody can link to any thing they wish that is on the web and addressable. The naming for the hyperlink can be whatever helps the person creating the link understand what that link is pointing to. This is the initial folksonomy, hyperlinks. Google was smart in using the link names in their algorithm for helping people find information they are seeking. Yes, people can disrupt the system with Googlebombing, but the it just takes a slightly smarter tool to get around these problems.
You see hierarchies are simple means of structuring information, but the world is not as neat nor simple. Things are far more complex and each person has their own derived means of structuring information in their memory that works for them. Some have been enculturated with scientific naming conventions, while others have not.
I have spent the last few years watching users of a site not understand some of the hierarchies developed as there are more than the one or two user-types that have found use in the information being provided. They can get to the information from search, but are lost in the hierarchies as the structure is foreign to them.
It is from this context that I asked the question. We are seeing new tools that allow for regular people to tag information objects with terms that these people would use to describe the object. We see tools that can help make sense of these tags in a manner that gets other people to information that is helpful to them. These folksonomy tools, like Flickr, del.icio.us, and Google (search and Gmail) provide the means to tame the whole in a manner that is addressable across cultures (including nationalities and language) and disciplines. This breadth is not easily achievable by hierarchies.
So looking back, would we build hierarchies given today's tools? Knowing the world is very complex and diverse do simple hierarchies make sense?
Flexibility in Folksonomies
Nick Mote posts his The New School of Ontologies essay, which is a nice overview of formal classification and folksonomies. The folksonomy is a good approach for bottom-up approach to information finding.
In Nick's paper I get quoted. I have cleaned up the quote that came out of an e-mail conversation. This quote pretty much summaries the many discussions I have had in the past couple months regarding folksonomies. Am I a great fan of the term? Not as much of a fan as what they are doing.
The problem of interest to me that folksonomies are solving is cross-discipline and cross-cultural access to information as well as non-hierarchical information structures. People call items different things depending on culture, discipline, and/or language. The folksonomy seems to be a way to find information based on what a person calls it. The network effect provides for more tagging of the information, which can be leveraged by those who have naming conventions that are divergent from the norm. The power law curve benefits the enculturated, but the tail of the curve also works for those out of the norm.
That Syncing Feeling (text)
My presentation of That Syncing Feeling is available. Currently the text format is available, but a PDF will be available at some point in the future (when more bandwidth is available). This was delivered at Design Engaged in Amsterdam this morning. More to follow...
Personal Information Aggregation Nodes
Agnostic aggregators are the focal point of information aggregation. The tools that are growing increasingly popular for the information aggregation from internet sources are those that permit the incorportation of info from any valid source. The person in control of the aggregator is the one who chooses what she wants to draw in to their aggregator.
People desiring info agregation seemingly want to have control over all sources of info. She wants one place, a central resource node, to follow and to use as a starting point.
The syndication/pull model not only adds value to the central node for the user, but to those points that provide information. This personal node is similar (but conversely) to network nodes in that the node is gaining value as the individual users make use of the node. The central info aggregation node gains value for the individual the more information is centralized there. (The network nodes gain value the more people use them, e.g. the more people that use del.icio.us the more valuable the resource is for finding information.) This personal aggregation become a usable component of the person's Personal InfoCloud.
What drives the usefulness? Portability of information is the driver behind usefulness and value. The originating information source enables value by making the information usable and reusable by syndicating the info. Portabiliry is also important for the aggregators so that information can move easily between devices and formats.
Looking a del.icio.us we see an aggrgator that leverages a social network of people as aggregators and filters. Del.icio.us allows the user to build their own bookmarks that also provides a RSS feed for those bookmarks (actually most everything in del.icio.us provides feeds for most everything) and an API to access the feeds and use then as the user wishes. This even applies to using the feed in another aggregator.
The world of syndication leads to redundant information. This where developments like attention.xml will be extremely important. Attention.xml will parse out redundant info so that you only have one resource. This work could also help provide an Amazon like recommendation system for feeds and information.
The personal aggregation node also provides the user the means to categorize information as they wish and as makes most sense to themselves. Information is often not found and lost because it is not categorized in a way that is meaningful to the person seeking the information (either for the first time or to access the information again). A tool like del.icio.us, as well as Flickr, allows the individual person to add tags (metadata) that allows them to find the information again, hopefully easily. The tool also allows the multiple tagging of information. Information (be it text, photo, audio file, etc.) does not always permit itself easy narrow classification. Pushing a person to use distinct classifications can be problematic. On this site I built my category tool to provide broad structure rather than heirarchial, because it allows for more flexibility and can provide hooks to get back to information that is tangential or a minor topic in a larger piece. For me this works well and it seems the folksonomy systems in del.icio.us and Flickr are finding similar acceptance.
Feed On This
The "My" portal hype died for all but a few central "MyX" portals, like my.yahoo. Two to three years ago "My" was hot and everybody and their brother spent a ton of money building a personal portal to their site. Many newspapers had their own news portals, such as the my.washingtonpost.com and others. Building this personalization was expensive and there were very few takers. Companies fell down this same rabbit hole offering a personalized view to their sites and so some degree this made sense and to a for a few companies this works well for their paying customers. Many large organizations have moved in this direction with their corporate intranets, which does work rather well.
Where Do Personalization Portals Work Well
The places where personalization works points where information aggregation makes sense. The my.yahoo's work because it is the one place for a person to do their one-stop information aggregation. People that use personalized portals often have one for work and one for Personal life. People using personalized portals are used because they provide one place to look for information they need.
The corporate Intranet one place having one centralized portal works well. These interfaces to a centralized resource that has information each of the people wants according to their needs and desires can be found to be very helpful. Having more than one portal often leads to quick failure as their is no centralized point that is easy to work from to get to what is desired. The user uses these tools as part of their Personal InfoCloud, which has information aggregated as they need it and it is categorized and labeled in a manner that is easiest for them to understand (some organizations use portals as a means of enculturation the users to the common vocabulary that is desired for use in the organization - this top-down approach can work over time, but also leads to users not finding what they need). People in organizations often want information about the organization's changes, employee information, calendars, discussion areas, etc. to be easily found.
Think of personalized portals as very large umbrellas. If you can think of logical umbrellas above your organization then you probably are in the wrong place to build a personalized portal and your time and effort will be far better spent providing information in a format that can be easily used in a portal or information aggregator. Sites like the Washington Post's personalized portal did not last because of the cost's to keep the software running and the relatively small group of users that wanted or used that service. Was the Post wrong to move in this direction? No, not at the time, but now that there is an abundance of lesson's learned in this area it would be extremely foolish to move in this direction.
You ask about Amazon? Amazon does an incredible job at providing personalization, but like your local stores that is part of their customer service. In San Francisco I used to frequent a video store near my house on Arguello. I loved that neighborhood video store because the owner knew me and my preferences and off the top of his head he remembered what I had rented and what would be a great suggestion for me. The store was still set up for me to use just like it was for those that were not regulars, but he provided a wonderful service for me, which kept me from going to the large chains that recorded everything about me, but offered no service that helped me enjoy their offerings. Amazon does a similar thing and it does it behind the scenes as part of what it does.
How does Amazon differ from a personalized portal? Aggregation of the information. A personalized portal aggregates what you want and that is its main purpose. Amazon allows its information to be aggregated using its API. Amazon's goal is to help you buy from them. A personalized portal has as its goal to provide one-stop information access. Yes, my.yahoo does have advertising, but its goal is to aggregate information in an interface helps the users find out the information they want easily.
Should government agencies provide personalized portals? It makes the most sense to provide this at the government-wide level. Similar to First.gov a portal that allows tracking of government info would be very helpful. Why not the agency level? Cost and effort! If you believe in government running efficiently it makes sense to centralize a service such as a personalized portal. The U.S. Federal Government has very strong restriction on privacy, which greatly limits the login for a personalized service. The U.S. Government's e-gov initiatives could be other places to provide these services as their is information aggregation at these points also. The downside is having many login names and password to remember to get to the various aggregation points, which is one of the large downfalls of the MyX players of the past few years.
What Should We Provide
The best solution for many is to provide information that can be aggregated. The centralized personalized portals have been moving toward allowing the inclusion of any syndicated information feed. Yahoo has been moving in this direction for some time and in its new beta version of my.yahoo that was released in the past week it allows the users to select the feeds they would like in their portal, even from non-Yahoo resources. In the new my.yahoo any information that has a feed can be pulled into that information aggregator. Many of us have been doing this for some time with RSS Feeds and it has greatly changed the way we consume information, but making information consumption fore efficient.
There are at least three layers in this syndication model. The first is the information syndication layer, where information (or its abstraction and related metadata) are put into a feed. These feeds can then be aggregated with other feeds (similar to what del.icio.us provides (del.icio.us also provides a social software and sharing tool that can be helpful to share out personal tagged information and aggregations based on this bottom-up categorization (folksonomy). The next layer is the information aggregator or personalized portals, which is where people consume the information and choose whether they want to follow the links in the syndication to get more information.
There is little need to provide another personalized portal, but there is great need for information syndication. Just as people have learned with internet search, the information has to be structured properly. The model of information consumption relies on the information being found. Today information is often found through search and information aggregators and these trends seem to be the foundation of information use of tomorrow.
Gordon Rugg and the Verifier Method
In the current Wired Magazine an article on Gordon Rugg - Scientific Method Man (yes, it is the same Gordon Rugg of card sorting notoriety). The article focuses on his solving the Voynich manuscript, actually deciphering it as a hoax. How he goes about solving the manuscript is what really has me intrigued.
Rugg uses a method he has been developing, called the verifier approach, which develops a means critical examination using:
The verifier method boils down to seven steps: 1) amass knowledge of a discipline through interviews and reading; 2) determine whether critical expertise has yet to be applied in the field; 3) look for bias and mistakenly held assumptions in the research; 4) analyze jargon to uncover differing definitions of key terms; 5) check for classic mistakes using human-error tools; 6) follow the errors as they ripple through underlying assumptions; 7) suggest new avenues for research that emerge from steps one through six.
One area that Rugg has used this has been solving cross-discipline terminology problems leading to communication difficulties. He also found that pattern-matching is often used to solve problems or diagnose illness, but a more thorough inquiry may have found a more exact cause, which leads to a better solution and better cure.
Can the verifier method be applied to web development? Information Architecture? Maybe, but the depth of knowledge and experience is still rather shallow, but getting better every day. Much of the confounding issues in getting to optimal solutions is the cross discipline backgrounds as well as the splintered communities that "focus" on claimed distinct areas that have no definite boundaries and even have extensive cross over. Where does HCI end and Usability Engineering begin? Information Architecture, Information Design, Interaction Design, etc. begin and end. There is a lot of "big umbrella" talk from all the groups as well as those that desire smaller distinct roles for their niche. There is a lot of cross-pollination across these roles and fields as they all are needed in part to get to a good solution for the products they work on.
One thing seems sure, I want to know much more about the verifier method. It seems like understanding the criteria better for the verifier method will help frame a language of criticism and cross-boundary peer review for development and design.
Fixing Permalink to Mean Something
This has been a very busy week and this weekend it continues with the same. But, I took two minutes to see if I could solve a tiny problem bugging me. I get links to the main blog, Off the Top, from outside search engines and aggregators (Technorati, etc.) that are referencing content in specific entries, but not all of those entries live on the ever-changing blog home page. All of the entries had the same link to their permanant location. The dumb thing was every link to their permanant home was named the same damn thing, "permalink". Google and other search engines use the information in the link name to give value to the page being linked to. Did I help the cause? No.
So now every permanent link states "permalink for: incert entry title". I am hoping this will help solve the problem. I will modify the other pages most likely next week sometime (it is only a two minute fix) as I am toast.
Now Delicious
Time has been very thin of late. In the past six months or so started noticing an increasing number of links from del.icio.us and started pulling the feeds of some folks I like to follow their reading list into my site feed aggregator. I had about four or five del.icio.us feeds in my aggregator (meta aggregation of other's meta aggregations - MetaAg MetaAg). This past week I was taking medicine that tweaked by sleep patterns so I had some free awake time after midnight and I finally set up my own vanderwal del.icio.us feed.
I like having the ability to pull [meta] tags aggregations that others have used, like security, which is a great help during the day at work. I can also track some topics I keep finding myself at the periphery and ever more interested in as they tie to some personal projects.
I did consider something similar with Feedster, but it was down for updating recently when I had the tiny bit of time to fiddle with setting something up. By the way, Feedster is now Standards-based (not fully valid, but rather close) and it loads very quickly (most of the time).
Gmail Simplifies Email
Since I have been playing with Gmail I have been greatly enjoying the greatly improved means of labeling and archiving of e-mail as opposed to throwing them in folders. Many e-mails are hard to singularly classify with one label that folders force us to use. The ability to drive the sorting of e-mail by label that allows the e-mail to sit accessibly under a filter named with the label make things much easier. An e-mail discussing CSS, XHTML, and IA for two different projects now can be easily accessed under a filter for each of these five attributes.
Dan Brown has written a wonderful article The Information Architecture of Email that dig a little deeper. Dan ponders if users will adopt the changed interface. Hearing many user frustrations with e-mail buried in their Outlook or other e-mail application, I think the improved interface may draw quite a bit of interest. As Apple is going this way for its file structure in Tiger (the next OS upgrade) with Spotlight it seems Gmail is a peak at the future and a good means to start thinking about easier to find information that the use can actually manage.
Make My Link the P-link
Simon hit on plinks as an echo to Tim Bray's comments and variation on Purple Numbers (Purple Numbers as a reference). As I have mentioned before, page numbers fail us and these steps are a good means to move forward.
Simom has also posted in more plinks and in there points to Chris Dent's Big Day for Purple Numbers.
I have been thinking for quite some time about using an id attribute in each paragraph tag that includes the site permalink as well as the paragraph with in that entry. This would look like: <p id="1224p7">. This signifies permanent entry 1224 and paragraph 7 with in that entry. What I had not sorted out was an unobtrusive means of displaying this. I am now thinking about Simon's javascript as a means of doing this. The identifier and plink would be generated by PHP for the paragraph tag, which would be scraped by the javascript to generate the plink.
The downside I see is only making edits at the end of the entry using the "Update" method of providing edits and editorial comments. The other downside is the JavaScript is not usable on all mobile devices, nor was the speed of scrolling down Simon's page that fluid in Safari on my TiBook with 16MB of video RAM.
Ontology Primer
What is an Ontology and Why We Need It is an essential overview to ontologies.
Matt on Social Networks
Matt writes up this thoughts on the state of social networks. I agree with much of his frustration. I keep thinking many of these tools will provide some good value. The two that meet what I expect are Upcoming and LinkedIn. I like these are they offer small targeted offerings. Upcoming helps find and track events, while LinkedIn is a work related networking tool.
It seems a simple cross between LinkedIn and XFN or any metadata resource that can track relationships, trust, and taste along with tracking other items of interest would be greatly helpful. Matt does get the metadata problem included in his write-up, which is metadata is dirty and at best, biased (which can be good if you agree with the bias).
Indi on site navigation and keeping it under control
Indi Young provides a great guide for building browsing structures in her article Site Navigation: Keeping It Under Control.
Annotations for William Gibson's Pattern Recognition
Since I am in the midst of reading William Gibson's Pattern Recognition a great resource is 'PR'-otaku, which is an annotation of Pattern Recognition put together by Joe Clark. This is a brilliant addition to the book done by a fan. I had noticed many of the same items that are annotated, notably monomers in the first few pages, which has my radar on since then. [hat tip Adam]
The Web, information use, and the failure of the spacial metaphor
Francis Cairncross' book title Death of Distance is a wonderful understanding of the world around us in many way and should now apply to spacial relationships on the Web. The idea of spacial relationships on the Web have been a stretch of the truth for a long time. Initially the idea of a person going out and "navigating" other spaces helped those new to the prospect of what the Web held grasp the Web concept.
The problem with spacial explanations of the Web is they do not work very well. The truth is we go nowhere on the Web, information is brought to us. The Web user is ego-centric and rightfully so, as the world of information and commerce on the Web revolves around the user. The Web is truly omnipresent. Information is everywhere at once. The Web can even follow the user on mobile devices. The user does not go out and explore different places, the artifacts of the places come to the user's screen based on what is of interest to the user.
I was reading David Weinberger's book Small Pieces Loosely Joined and it was painful to watch him twist and turn to get the spacial metaphor to work. A whole chapter in the book is devoted to Space [on the Web] (the book as a whole is very enjoyable and worth the time to read). Weinberger first discusses how we use the Web, using surf, browse, and go to a site. This is wrapped with an analogy explaining the Web is like a library where the user does not have access to the stacks of books, but a librarian (or clerk) goes and retrieves the book, based on the request the user made, and brings it to the user. He also states:
... this is perhaps the most significant change the Web brings to the world of documents: the Web has created a weird amalgam of documents and buildings. With normal paper documents, we read them, file them, throw them out, or sent them to someone else. We do not go to them. We don't visit them. Web documents are different. They're places on the Web. We go to them as we might go to the Washington Monument or the old Endicott Building. They're there, we're here, and if we want to see them, we've got to travel.
.... the odd thing is that, of course, we're not really going any place, and we know it.
This is just painful to follow. We keep bringing up this bloodied and battered spacial metaphor trying to make it work to explain more than the very tiny bit it did explain well. The spacial metaphor has long overstayed its welcome and it now hinders us as we try to build the future information interfaces, which include mobile information access and internationalization of information.
Yes, I am saying mobile information use is hindered by a spacial metaphor. It is more than hindered it is crippled by it. When prepare information now location is largely irrelevant, but access, device, application, and information form and highly relevant. Before we prepared information on paper and sent that information to people (which can be done today) and we largely knew how that information was going to be used. Today, with digital information the ease of information reuse and the user's ego-centric view of the information world, we must think of the user and how the information will be used. The proximity of the information to the user through access, storage, or personalization is what is paramount. Proximity is the only spacial element that has significance. This equally applies to internationalization as language and culture are the barriers to the information not space. A Brazilian may be sitting on the T in Boston and want to read the most recent information on rollout of WiFi in Rio. The user should not need to find the Brazilian neighborhood in Boston to get the information in the proper language (Portuguese) with familiar cultural inflections. The user can attract that information form easily, which can be brought to the user if that information and access have been prepared and enabled. The user may have come across a resource for this information while looking for a client's most recent press release and the user forwarded the link to her mobile device to read later. Access to information can and should be based on the users actions and choices.
The user can (and has been able to for some time) create their own metadata and retrieval structures. Communication with live people or machines that can and will convey useful information at the user's desire is not only the reality of the wired world, but what mobile use is all about. The user can set their proximity to information they have come across and connectivity conduits are enablers of that information they have yet to discover.
Up to this point the spacial metaphor only provided us with the navigation, but flat out failed us with what the user could do once they found what they were seeking. The user can browse, search, receive in e-mail (based on list subscriptions), read an information feed that brings to the user new information from sites the user likes or from aggregators, or a variety of other means. Once the user comes across information they have an interest in they want to keep that information attracted to themselves, via storage, putting it on a page that is accessible to a mobile or stationary device, and/or have the information delivered at a time that will be more convenient (getting a text message on your phone with the address and time of a party at an art gallery). Proximity also plays a role in location based services, such as bringing up restaurant listing and reviews when the GPS in our mobile device indicates we are near these establishments. The user should be able to identify favorites or preferences that can help provide "best options".
The realization of the failure of the navigation metaphor to provide for much other than a nice name for the grouped set of links that provide browsing options pushed me to investigate the Model of Attraction (MoA). The MoA is not perfect, but does provide a framework to think about information use and reuse as users currently interact with it. The MoA offers a method for us to work through how we allow the user to easily reuse information they found. The devices are just conduits for the attraction interaction to take place. MoA offers a framework that is also easy to understand, but is a literal description, which helps us see building, structuring, and preparing information and applications for the future.
Navigation -- R.I.P.
RDF is more than three letters
You need to buy a vowel to make a word with the letters RDF, but RDF can be used to share informaiton and communicate. Kendall Grant Clark explains the uses for the Resource Description Framework.Amazon classification
I found the following item description and classification in Amazon Gold Box, "Norelco 8865XL Spectra Shaver with LED, Eggplant - [Kitchen]". I have a similar shaver (sort of), but I would never think to shave in the kitchen. Maybe that is just me. I wonder what a hair remover is classified as?Metadata article store
Metadata articles collected by the Database Knowledge Base over at IT Toolbox. [hat tip Victor]Information through a child's eyes
I have been pondering of late about what a large organization's site would look like if its information structure was created by a child. We all pretty much know by now that Internet sites that partition information based on an organization chart are a failure for users finding information. Org charts protect egos, but don't facilitate information sharing, which is part of what triggered these thoughts as children really do not have egos to protect (even though they do get possessive of their toys, but only one or two at a time). The other trigger was watching my wife's niece (just turned 2) play with her plastic food from her wooden kitchen. She organized my colors first, then reorganized by shapes, then assembled foods in dishes with roughly an even mixture of color and shapes. All of this organizing was done while the "adults" were talking and not paying attention.
This was just a small observation of one, but if a child who is not yet two can organize plastic products by discerning qualities can we have them create informational organization structures by age three or four? Our niece learned her organizational skills by watching and patterning her expected org structures on observation. I was a little bit amazed by the facetted grouping and grouping by recognizable categories.
Many large organization site's are very difficult because they choose organizational structures that are based on their internal understanding of that information. Organizations that have readily easy to use sites spend time categorizing information by how the outside user's structure their understanding of the information. Can we learn to do things properly from children?
placeless documents
Xerox parc offers placeless documents. This approach classifies documents by the documents properties and not the location where the document is stored.Warchalking
Matt Jones introduces Warchalking. This is a great idea. Hmmm, I wonder if my nephews have any sidewalk chalk in their posession?Facets through discussion
Christina and Karl explain facets providing a broad overview. Understanding facets is one of the best steps you can take to understanding information structures and how to approach them.Findability explained
Peter Morville finally puts his findability explanation in writing for all to see (in the wonderful site called Boxes and Arrows). The idea of the term and meaning of findability is growing on me. Findability is a solid lead into the problems of information structure. The explanation of how to start fixing the problems and actions needed to help eradicate the problem can reside in the method/model of attraction (an update to the MOA should be available in two or three weeks, extenuating circumstances have slowed the updates and progress).XML for org charts and so much more
Thanks to Anil, I came across An open toolkit to facilitate knowledge extraction and document analysis, which contains a solid approach to org charts. I know quite a few folks that sing the "Org Chart Blues" on a daily basis. This is a solid step in the right direction. This document is the work of Gareth HughesPhilip Greenspun also provides his Software Engineering of Innovative Web Services course materials online. The Problem set 4 is a wonderful section that covers metadata and its uses. As the overview states:
Teach students the virtues of metadata. More specifically, they learn how to formally represent the requirements of a Web service and then build a computer program to generate the computer programs that implement that service.
I not only found the Edison and the Big Thing, but the New York Times now offers signing up for narrowed news trackers. These e-mail alerts are set to keywords that have a corrolation to the article. This seems to be a nice easy step for user to set the alerts via e-mail. It would be interesting to know how well this service is used and received.
Metaphor of Attraction
Beginning with a discussion with Stewart on Peterme and the encouragement of Lane in another discussion to look for a metaphor other than navigation that could better explain what we do on the Web. Seeing Stewart walk by at SXSW after I had seen some of Josh Davis visual plays I combined the discussion with Stewart with the magnetic attraction Josh showed, which began my thinking about a metaphor of attraction. Magnetism seems like what happens when we put a search term in Google, it attracts information that is draw to the term on to your screen.
Come see where else this metaphor can go in this poorly written for draft of the metaphor of attraction. This is posted to begin a collaboration to dig back and move forward, if that is where this is to go. The writing will improve and the ideas will jell into a better presentation over the next few weeks.
InfoWorld has an interview with the executive director of the National Center for Supercomputing Applications (NCSA), Dan Reed discussing the computing grid. This is somewhat like having an electric grid but the commodity is data. The grid's biggest hurdle is interacting with differing data types for essentially similar data. This he explains is bridged using metadata. The metadata needs are enormous. Understanding the information and data is paramount to the task and getting the system right.
I have added two pages to help provide a guide for metadata usage. One page sorts categories by number of times the metadata definition has been used. The other page is an alphabetical listing of categories with their count. These two page builds took very little time to knock together (half an hour or so) and the value to me is much greater than that half hour used.
Okay, O'Reilly Net has been offering a lot of good resources of late and I am a little behind in catching up.
Those of us that need a light weight database for a small project and are using Microsoft Windows often turn to Access to perform the task. Steven Roman offers his tips in how to set up an Access database. The best tip is right up front:
Don't touch your PC until you have taken the time to rough out a design of your database.The tips keep coming and many of them apply to any other database development. Once I learned to think of information and metadata in a relational database format (which also helps with setting up XML documents) application development became easier. Understanding a little database design will also help ask the right questions when setting up an application, database, and/or project.
This article also helps define the limitations of Access databases. Each database will have its own limitations or peculiarities. Knowing these differences will help think about the application, information, and how they can and will be used is helpful.
John Udell looks in to perl to create topic maps and bottom up taxonomy. Making taxonomy and topic maps easier is a great endeavor and quite useful.
DM Review provides a history of metadata and the future of metadata in one article, what more could you want. It is a good overview of the past tools and goals of metadata. Central to providing a solid information application is understanding the data and information we are working with. This understanding allows us to tie is to other information to give that data better depth and this is best done with metadata. Metadata help explains the data and allows for data to be tied (or joined) to other data.
An example would be putting together a quick view of all products sold in an ice cream truck. The driver has a small computer that captures all the sales he has makes throughout the day. At certain intervals he synchs his sales to a central computer so that he can easily stop back at the warehouse and stock up on items he is low on. The driver has sold 7 of ab4532 and 16 of tr78t in the past hour. He has had requests for pp887 too. This information is useful for the computers and the data has meaning, but it needs some metadata to know that he will need 7 of Abners Glow-cicles, 16 Tricky Rootbeer pops, a carton of covered paper cups. This metadata will help the person that will prepare these items for the driver's arrival at the warehouse. The "pp" indicates that a paper product is needed and the number following is its actual product code. The raw data now has meaning with tanks to the metadata.
Content management is back at the forefront of every aspect of my digital life again. Content management revolves around keeping information current, accurate, and reusable (there are many more elements, but these cut to the core of many issues). Maintaining Websites and providing information resources on the broader Internet have revolved around static Web pages or information stored in MS Word, PDF files, etc. Content management has been a painful task of keeping this information current and accurate across all these various input and output platforms. This brings us to content management systems (CMS).
As I pointed to earlier, there are good resources for getting and understanding CMS and how our roles change when we implement a CMS. Important to understanding is the separation of content (data and information), from the presentation (layout and style), and from the application (PDF, Web page, MS Word document, etc.). This requires an input mechanism, usually a form that captures the information and places it in is data/information store, which may be a database, XML document, or a combination of these. This also provides for a workflow process that involved proofing and editing the information along with versioning the information.
Key to the CMS is separation of content, which means there needs to be a way to be a method of keeping links aside from the input flow. Mark Baker provides a great article, What Does Your Content Management System Call This Guy about how to handle links. Links are an element that separates the CMS-lite tools (Blogger, Movable Type, etc.) from more robust CMS (other elements of difference are more expansive workflow, metadata capturing, and content type handling (images, PDF, etc. and their related metadata needs)). Links in many older systems, often used for newspaper and magazine publications (New York Times and San Francisco Chronicle) placed their links outside of the body of the article. The external linking provided an easy method of providing link management that helps ensure there are no broken links (if an external site changes the location (URL) it there really should only be one place that we have to modify that link, searching every page looking for links to replace). The method in the Baker article outlines how many current systems provide this same service, which is similar to Wiki Wiki's approach. The Baker outlined method also will benefit greatly from all of the Information Architecture work you have done to capture classifications of information and metadata types (IA is a needed and required part of nearly every development process).
What this gets us is content that we can easily output to a Web site in HTML/XHTML in a template that meets all accessibility requirements, ensures quality assurance has been performed, and provides a consistent presentation of information. The same information can be output in a more simple presentation template for handheld devices (AvantGo for example) or WML for WAP. The same information can be provided in an XML document, such as RSS, which provides others access to information more easily. The same information can be output to a template that is stored in PDF that is then sent to a printer to output in a newsletter or the PDF distributed for the users to print out on their own. The technologies for information presentation are ever changing and CMS allows us to easily keep up with these changes and output the information in the "latest and greatest", while still being able to provide information to those using older technologies.
Seach Not and Find the Answer
Peter Morville explains why search doesn't suck, but is just not great. I completely agree. Search by itself misses much of the information, unless the site is well written (which provides a cohesive use of terms) or is augmented with metadata.Let me explain, as Doug Kaye uses in his quest to find what is wrong with searching, a person six months or more ago could have been writing about IT as the possible wave of the future. More recently the same person could have been writing about Ginger. This past week the writer would have started writing about Segway. All were the Dean Kamen invention, but a user searching for a the breadth of our writing on Segway could easily miss our mention of IT or Ginger. The user would have to know to search on these other terms, if they did not they may not find our work. We loose.
This is where metadata helps out. If the information is tagged with a term that classifies this information or could have synonymous relationships established from that metadata item (personal powered transportation = IT, Ginger, Segway...) would greatly help the search. Most of us have been worked on projects that have had searches yet we constantly had users asking us were our information on "xyz" could be found, as they did not find it in the search and they know they read it on our site. That is a large persistent problem. Searching is not a solution only a patch that leaks.
By the way taxonomies can be fluid, they have to be as usage changes.